ViscoNet: Bridging and Harmonizing Visual and Textual Conditioning for ControlNet
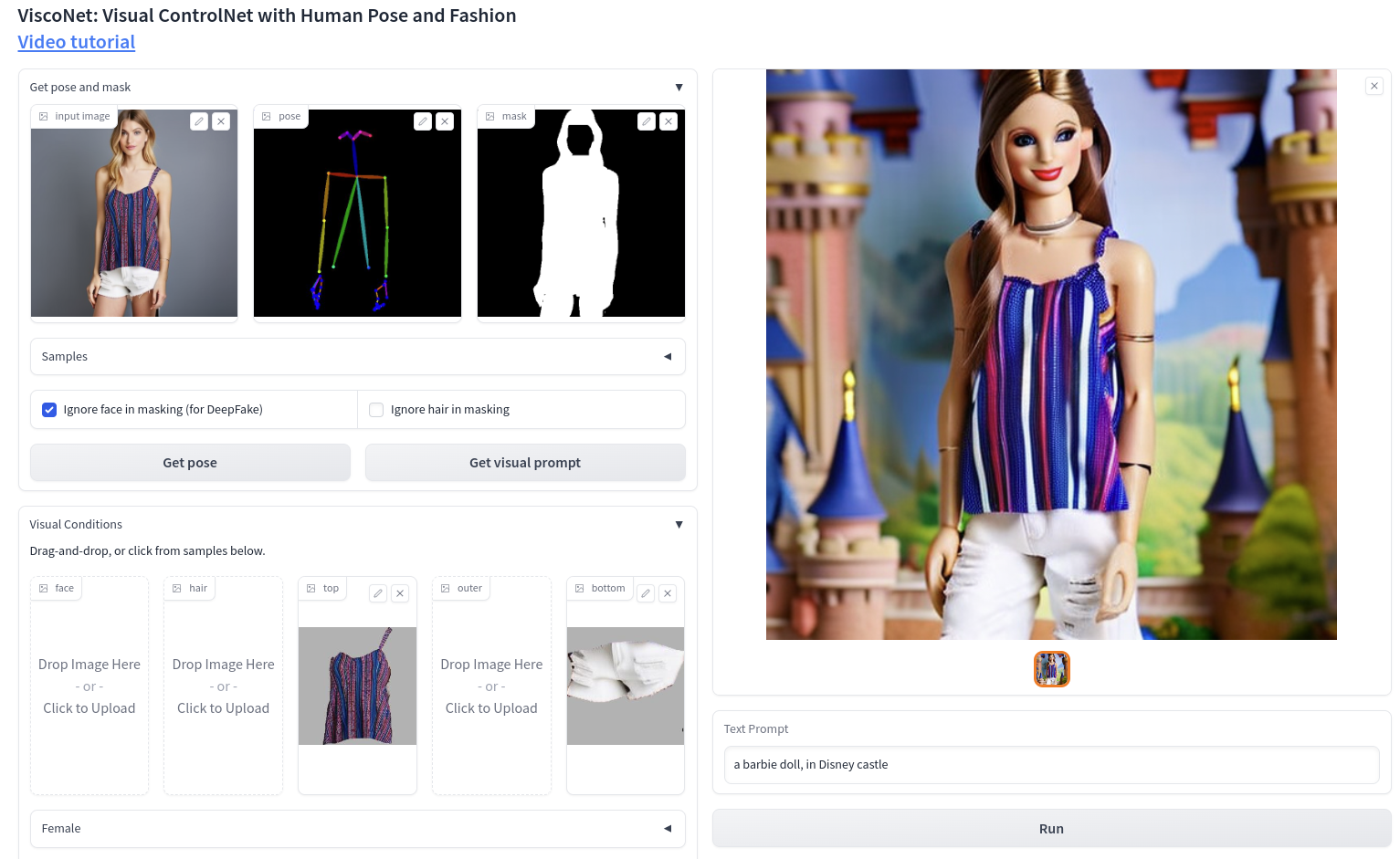
This paper introduces ViscoNet, a novel method that enhances text-to-image human generation models with visual prompting. Unlike existing methods that rely on lengthy text descriptions to control the image structure, ViscoNet allows users to specify the visual appearance of the target object with a reference image. ViscoNet disentangles the object's appearance from the image background and injects it into a pre-trained latent diffusion model (LDM) model via a ControlNet branch. This way, ViscoNet mitigates the style mode collapse problem and enables precise and flexible visual control. We demonstrate the effectiveness of ViscoNet on human image generation, where it can manipulate visual attributes and artistic styles with text and image prompts. We also show that ViscoNet can learn visual conditioning from small and specific object domains while preserving the generative power of the LDM backbone.
PDF Abstract


 DeepFashion
DeepFashion
