NeoNav: Improving the Generalization of Visual Navigation via Generating Next Expected Observations
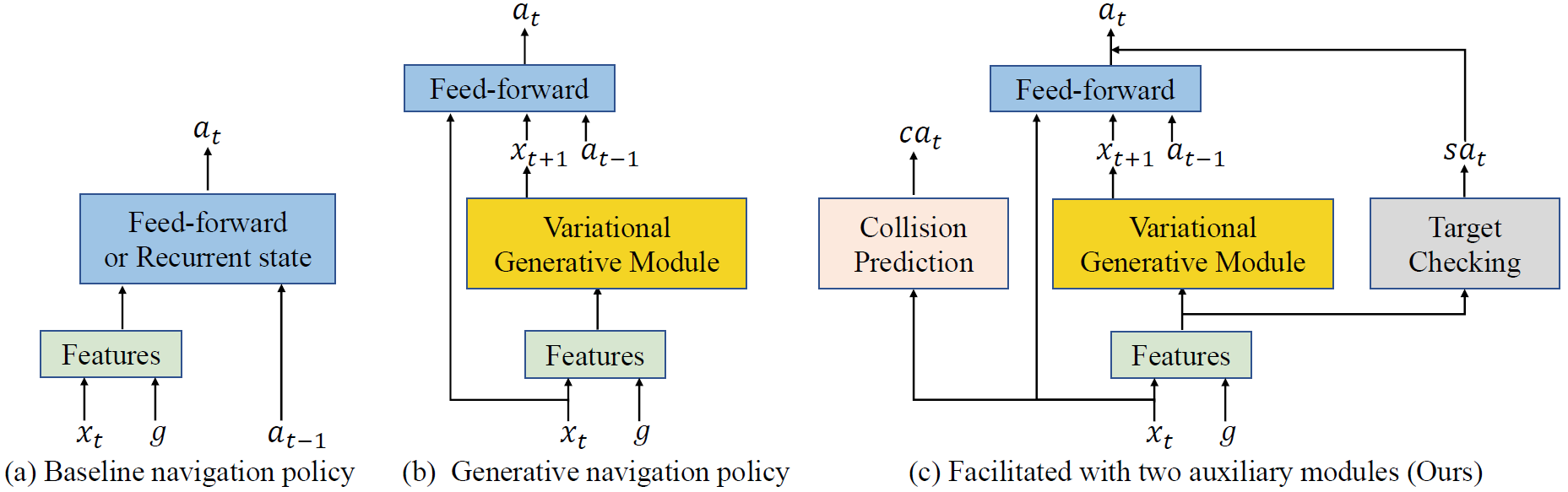
We propose improving the cross-target and cross-scene generalization of visual navigation through learning an agent that is guided by conceiving the next observations it expects to see. This is achieved by learning a variational Bayesian model, called NeoNav, which generates the next expected observations (NEO) conditioned on the current observations of the agent and the target view. Our generative model is learned through optimizing a variational objective encompassing two key designs. First, the latent distribution is conditioned on current observations and the target view, leading to a model-based, target-driven navigation. Second, the latent space is modeled with a Mixture of Gaussians conditioned on the current observation and the next best action. Our use of mixture-of-posteriors prior effectively alleviates the issue of over-regularized latent space, thus significantly boosting the model generalization for new targets and in novel scenes. Moreover, the NEO generation models the forward dynamics of agent-environment interaction, which improves the quality of approximate inference and hence benefits data efficiency. We have conducted extensive evaluations on both real-world and synthetic benchmarks, and show that our model consistently outperforms the state-of-the-art models in terms of success rate, data efficiency, and generalization.
PDF Abstract

 AVD
AVD
