VisualGPT: Data-efficient Adaptation of Pretrained Language Models for Image Captioning
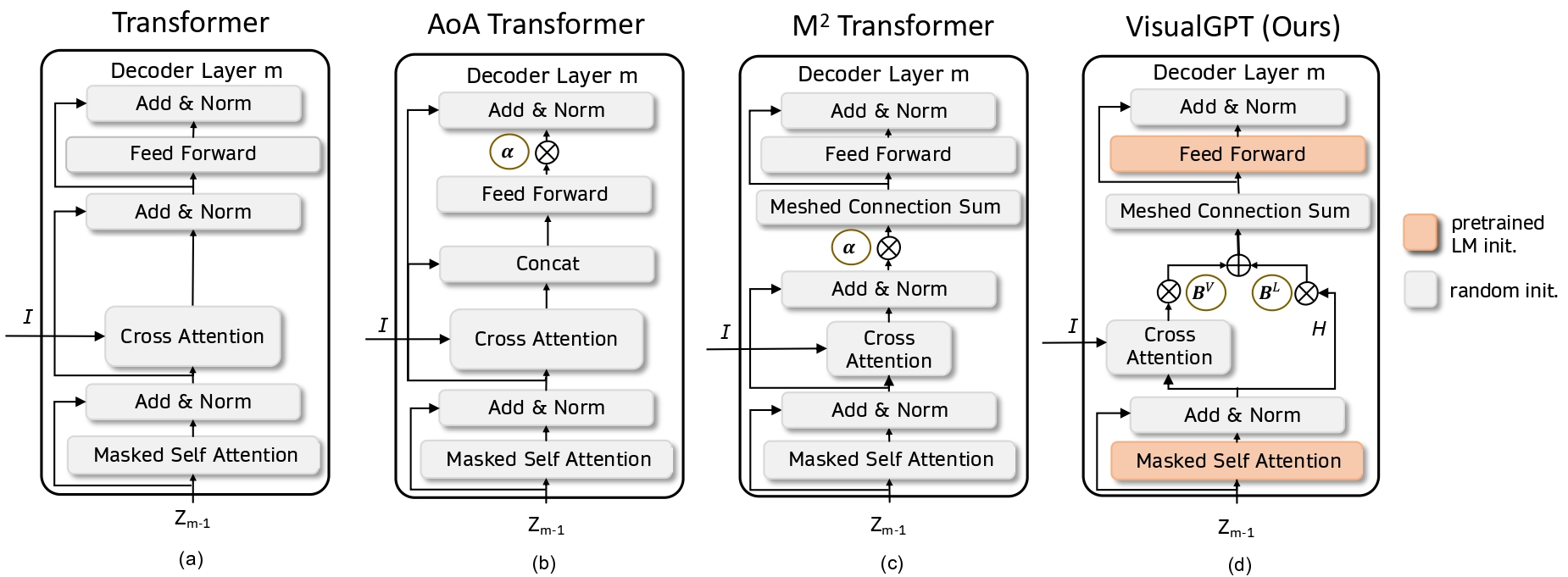
The ability to quickly learn from a small quantity oftraining data widens the range of machine learning applications. In this paper, we propose a data-efficient image captioning model, VisualGPT, which leverages the linguistic knowledge from a large pretrained language model(LM). A crucial challenge is to balance between the use of visual information in the image and prior linguistic knowledge acquired from pretraining. We designed a novel self-resurrecting encoder-decoder attention mechanism to quickly adapt the pretrained LM as the language decoder ona small amount of in-domain training data. The proposed self-resurrecting activation unit produces sparse activations but has reduced susceptibility to zero gradients. We train the proposed model, VisualGPT, on 0.1%, 0.5% and 1% of MSCOCO and Conceptual Captions training data. Under these conditions, we outperform the best baseline model by up to 10.8% CIDEr on MS COCO and upto 5.4% CIDEr on Conceptual Captions. Further, Visual-GPT achieves the state-of-the-art result on IU X-ray, a medical report generation dataset. To the best of our knowledge, this is the first work that improves data efficiency of image captioning by utilizing LM pretrained on unimodal data. Our code is available at: https://github.com/Vision-CAIR/VisualGPT.
PDF Abstract CVPR 2022 PDF CVPR 2022 Abstract




 MS COCO
MS COCO
 WikiText-2
WikiText-2
 Conceptual Captions
Conceptual Captions
