VoRTX: Volumetric 3D Reconstruction With Transformers for Voxelwise View Selection and Fusion
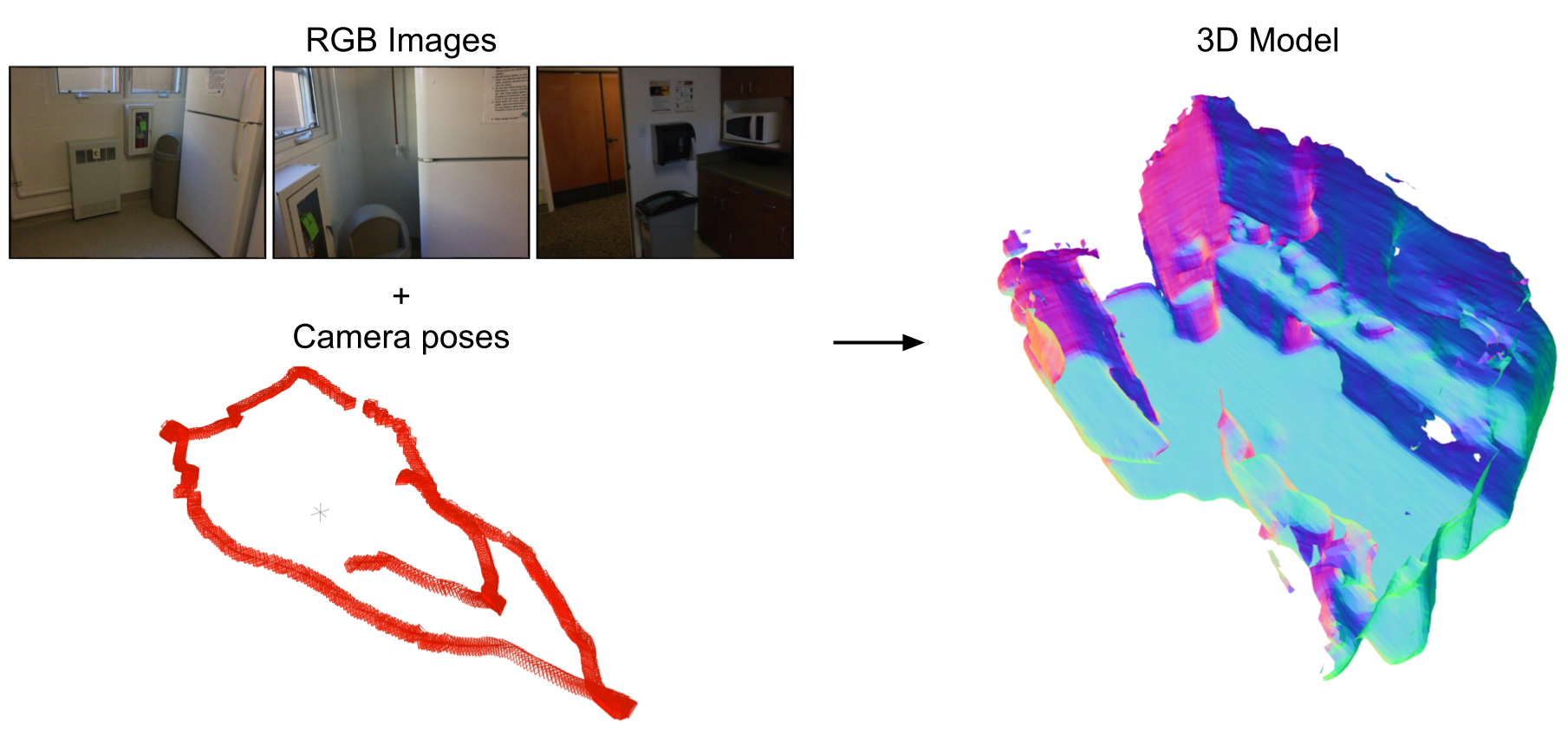
Recent volumetric 3D reconstruction methods can produce very accurate results, with plausible geometry even for unobserved surfaces. However, they face an undesirable trade-off when it comes to multi-view fusion. They can fuse all available view information by global averaging, thus losing fine detail, or they can heuristically cluster views for local fusion, thus restricting their ability to consider all views jointly. Our key insight is that greater detail can be retained without restricting view diversity by learning a view-fusion function conditioned on camera pose and image content. We propose to learn this multi-view fusion using a transformer. To this end, we introduce VoRTX, an end-to-end volumetric 3D reconstruction network using transformers for wide-baseline, multi-view feature fusion. Our model is occlusion-aware, leveraging the transformer architecture to predict an initial, projective scene geometry estimate. This estimate is used to avoid backprojecting image features through surfaces into occluded regions. We train our model on ScanNet and show that it produces better reconstructions than state-of-the-art methods. We also demonstrate generalization without any fine-tuning, outperforming the same state-of-the-art methods on two other datasets, TUM-RGBD and ICL-NUIM.
PDF Abstract

 ScanNet
ScanNet
