VRSO: Visual-Centric Reconstruction for Static Object Annotation
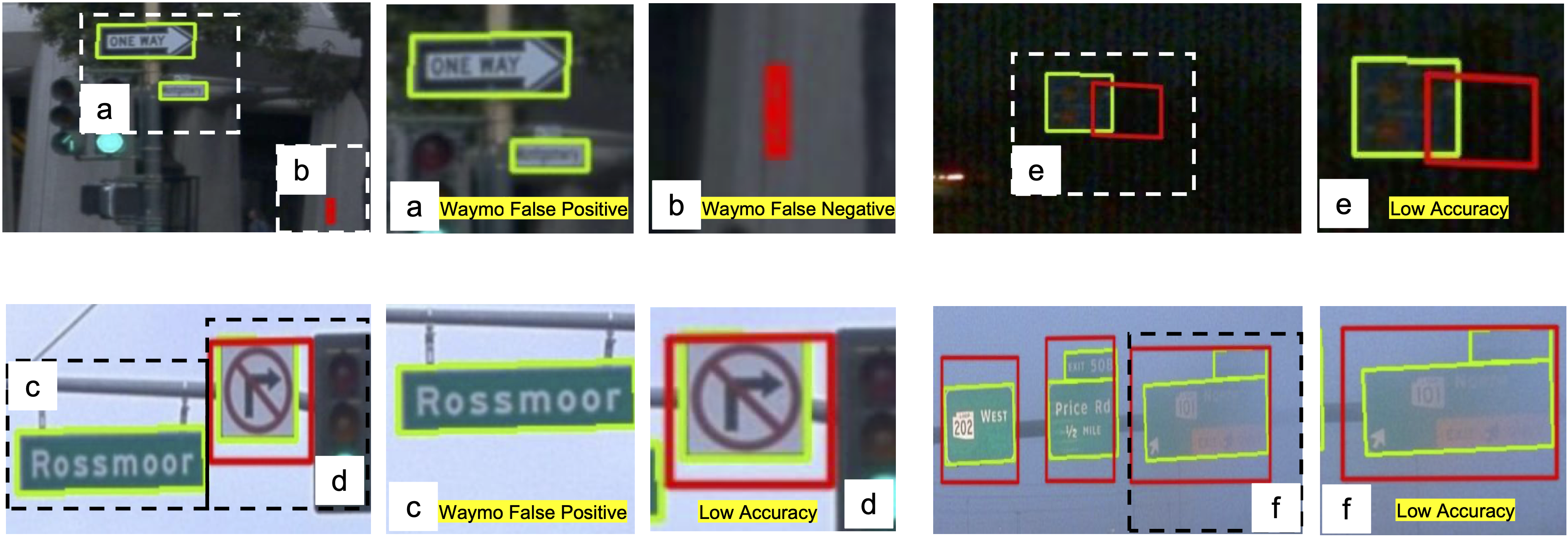
As a part of the perception results of intelligent driving systems, static object detection (SOD) in 3D space provides crucial cues for driving environment understanding. With the rapid deployment of deep neural networks for SOD tasks, the demand for high-quality training samples soars. The traditional, also reliable, way is manual labeling over the dense LiDAR point clouds and reference images. Though most public driving datasets adopt this strategy to provide SOD ground truth (GT), it is still expensive (requires LiDAR scanners) and low-efficient (time-consuming and unscalable) in practice. This paper introduces VRSO, a visual-centric approach for static object annotation. VRSO is distinguished in low cost, high efficiency, and high quality: (1) It recovers static objects in 3D space with only camera images as input, and (2) manual labeling is barely involved since GT for SOD tasks is generated based on an automatic reconstruction and annotation pipeline. (3) Experiments on the Waymo Open Dataset show that the mean reprojection error from VRSO annotation is only 2.6 pixels, around four times lower than the Waymo labeling (10.6 pixels). Source code is available at: https://github.com/CaiYingFeng/VRSO.
PDF Abstract


 nuScenes
nuScenes
 Waymo Open Dataset
Waymo Open Dataset
