Where Does My Model Underperform? A Human Evaluation of Slice Discovery Algorithms
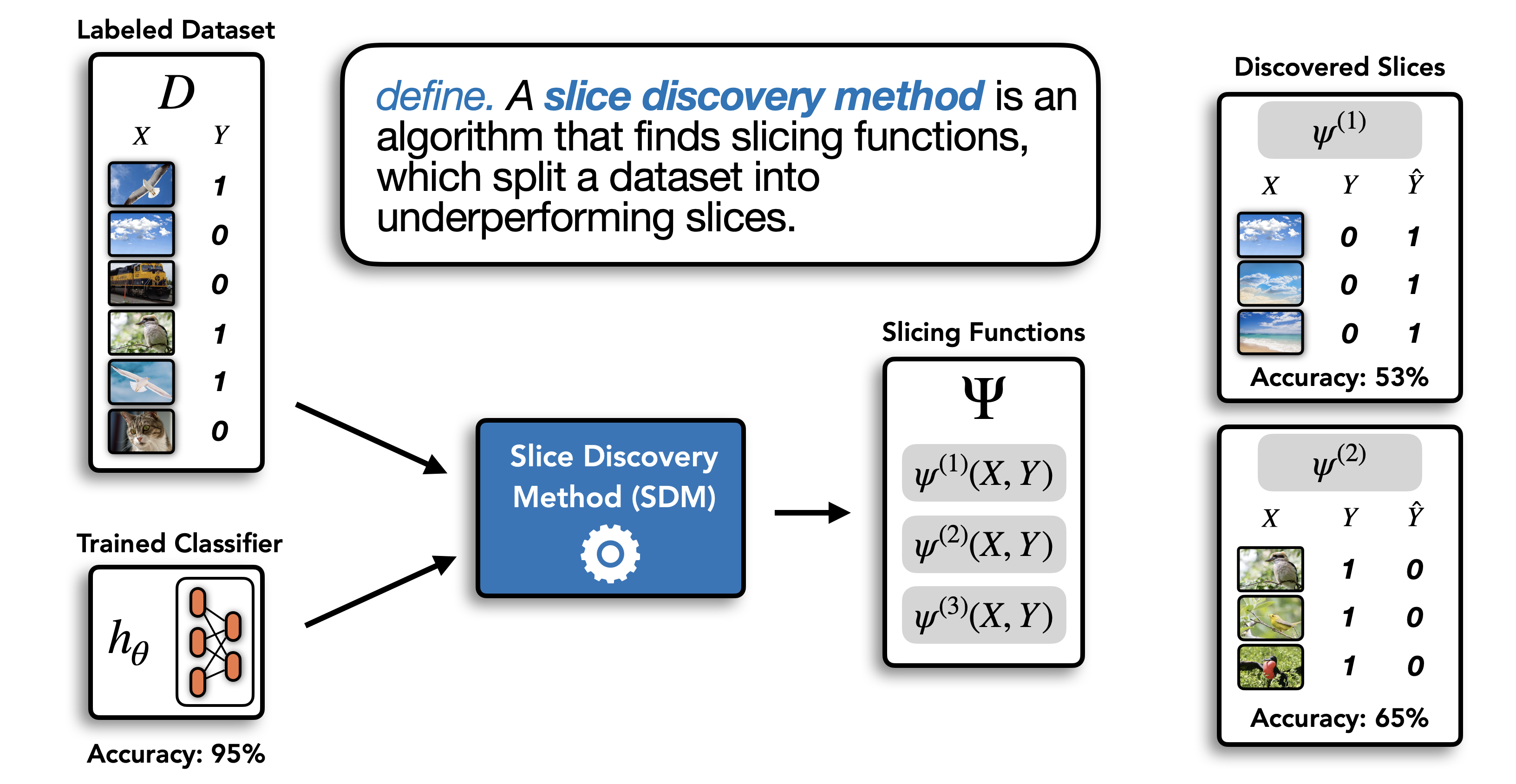
Machine learning (ML) models that achieve high average accuracy can still underperform on semantically coherent subsets ("slices") of data. This behavior can have significant societal consequences for the safety or bias of the model in deployment, but identifying these underperforming slices can be difficult in practice, especially in domains where practitioners lack access to group annotations to define coherent subsets of their data. Motivated by these challenges, ML researchers have developed new slice discovery algorithms that aim to group together coherent and high-error subsets of data. However, there has been little evaluation focused on whether these tools help humans form correct hypotheses about where (for which groups) their model underperforms. We conduct a controlled user study (N = 15) where we show 40 slices output by two state-of-the-art slice discovery algorithms to users, and ask them to form hypotheses about an object detection model. Our results provide positive evidence that these tools provide some benefit over a naive baseline, and also shed light on challenges faced by users during the hypothesis formation step. We conclude by discussing design opportunities for ML and HCI researchers. Our findings point to the importance of centering users when creating and evaluating new tools for slice discovery.
PDF Abstract
 Colab
Colab


 MS COCO
MS COCO
