X-modaler: A Versatile and High-performance Codebase for Cross-modal Analytics
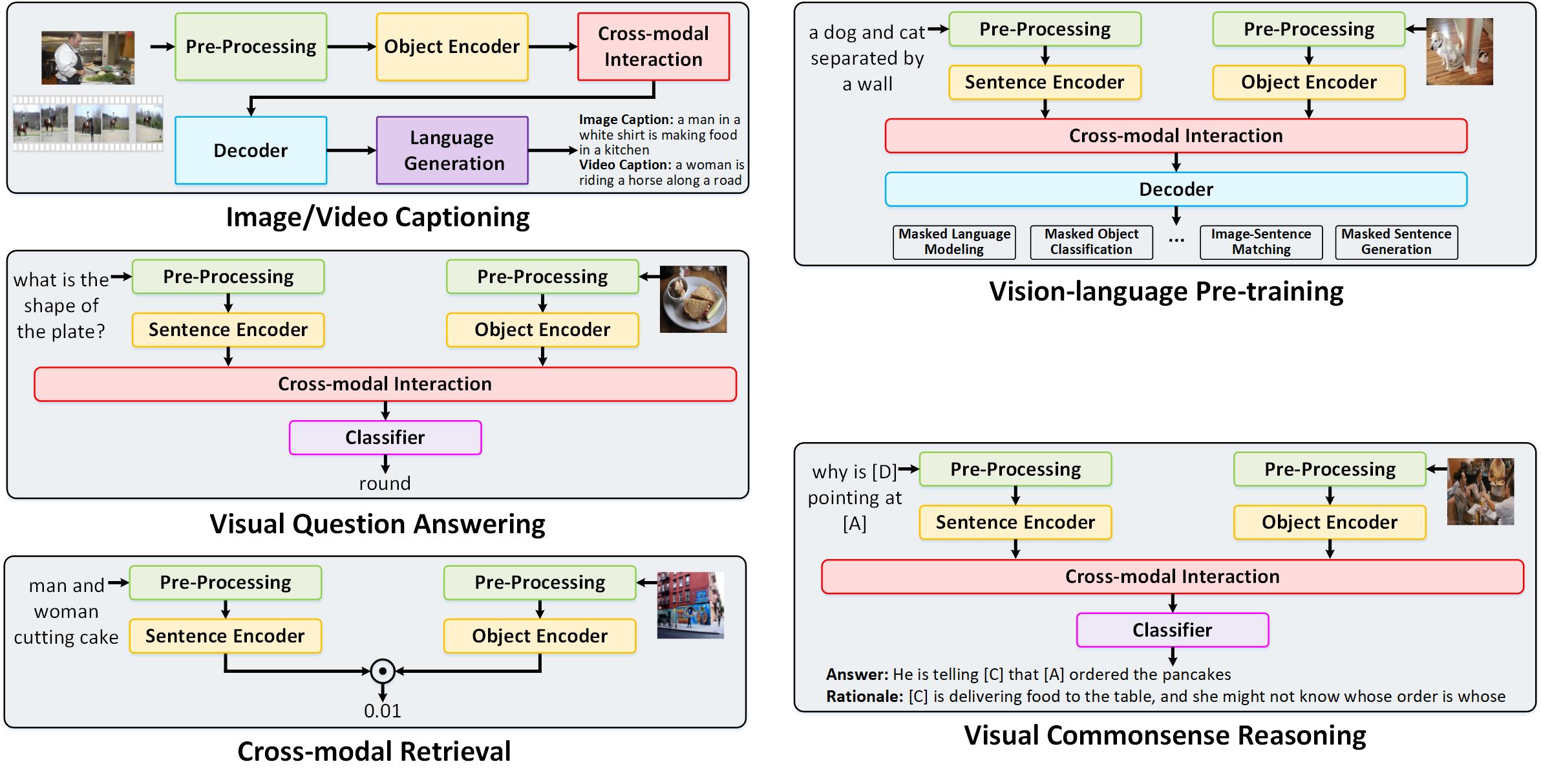
With the rise and development of deep learning over the past decade, there has been a steady momentum of innovation and breakthroughs that convincingly push the state-of-the-art of cross-modal analytics between vision and language in multimedia field. Nevertheless, there has not been an open-source codebase in support of training and deploying numerous neural network models for cross-modal analytics in a unified and modular fashion. In this work, we propose X-modaler -- a versatile and high-performance codebase that encapsulates the state-of-the-art cross-modal analytics into several general-purpose stages (e.g., pre-processing, encoder, cross-modal interaction, decoder, and decode strategy). Each stage is empowered with the functionality that covers a series of modules widely adopted in state-of-the-arts and allows seamless switching in between. This way naturally enables a flexible implementation of state-of-the-art algorithms for image captioning, video captioning, and vision-language pre-training, aiming to facilitate the rapid development of research community. Meanwhile, since the effective modular designs in several stages (e.g., cross-modal interaction) are shared across different vision-language tasks, X-modaler can be simply extended to power startup prototypes for other tasks in cross-modal analytics, including visual question answering, visual commonsense reasoning, and cross-modal retrieval. X-modaler is an Apache-licensed codebase, and its source codes, sample projects and pre-trained models are available on-line: https://github.com/YehLi/xmodaler.
PDF Abstract





 Visual Question Answering
Visual Question Answering
 MSR-VTT
MSR-VTT
 MSVD
MSVD
