X-Stance: A Multilingual Multi-Target Dataset for Stance Detection
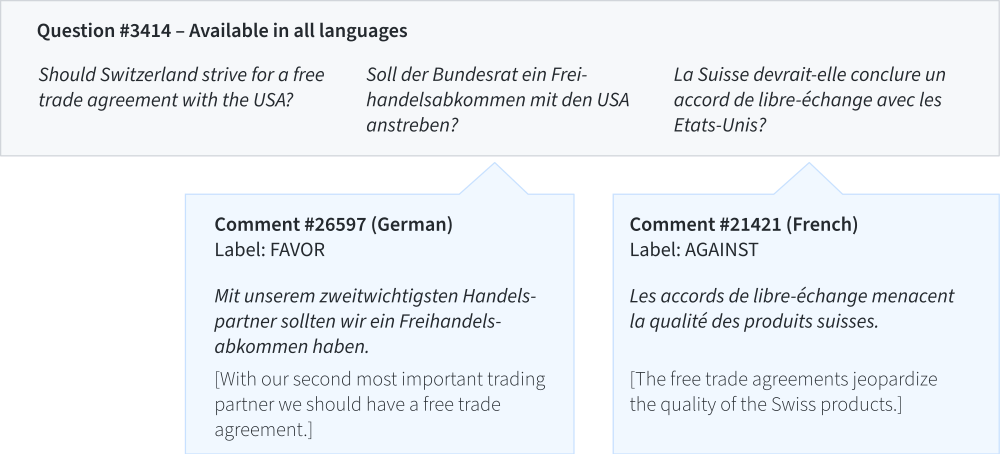
We extract a large-scale stance detection dataset from comments written by candidates of elections in Switzerland. The dataset consists of German, French and Italian text, allowing for a cross-lingual evaluation of stance detection. It contains 67 000 comments on more than 150 political issues (targets). Unlike stance detection models that have specific target issues, we use the dataset to train a single model on all the issues. To make learning across targets possible, we prepend to each instance a natural question that represents the target (e.g. "Do you support X?"). Baseline results from multilingual BERT show that zero-shot cross-lingual and cross-target transfer of stance detection is moderately successful with this approach.
PDF AbstractCode
Tasks

Datasets
Introduced in the Paper:
x-stance