XBound-Former: Toward Cross-scale Boundary Modeling in Transformers
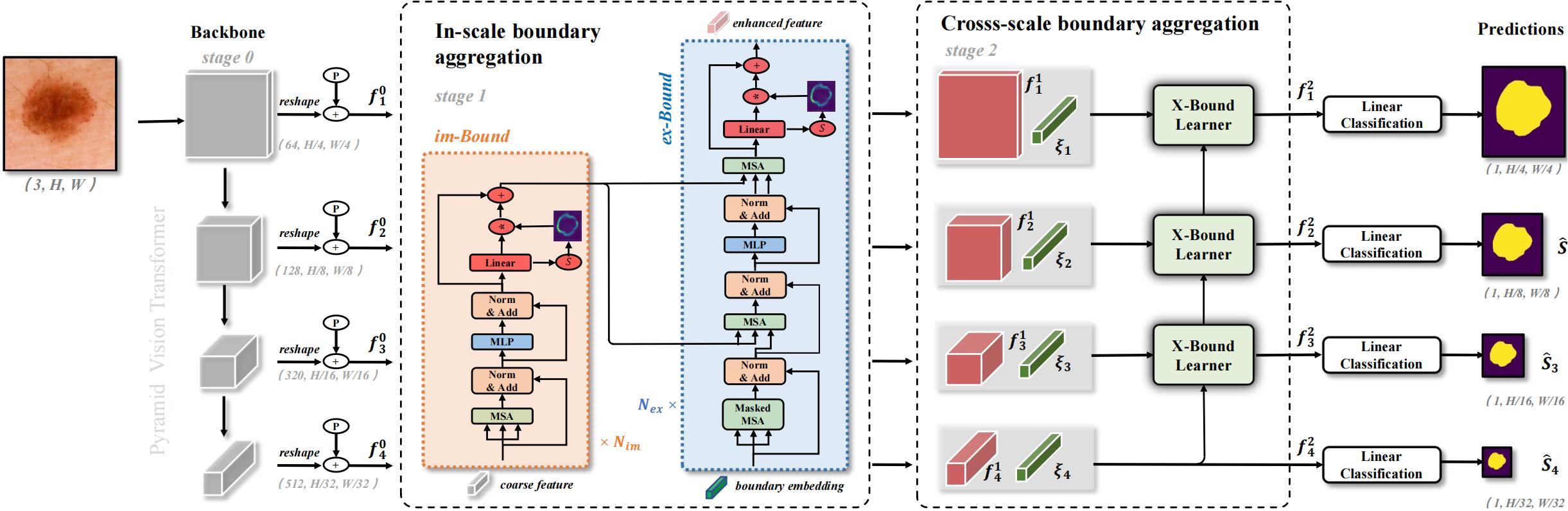
Skin lesion segmentation from dermoscopy images is of great significance in the quantitative analysis of skin cancers, which is yet challenging even for dermatologists due to the inherent issues, i.e., considerable size, shape and color variation, and ambiguous boundaries. Recent vision transformers have shown promising performance in handling the variation through global context modeling. Still, they have not thoroughly solved the problem of ambiguous boundaries as they ignore the complementary usage of the boundary knowledge and global contexts. In this paper, we propose a novel cross-scale boundary-aware transformer, \textbf{XBound-Former}, to simultaneously address the variation and boundary problems of skin lesion segmentation. XBound-Former is a purely attention-based network and catches boundary knowledge via three specially designed learners. We evaluate the model on two skin lesion datasets, ISIC-2016\&PH$^2$ and ISIC-2018, where our model consistently outperforms other convolution- and transformer-based models, especially on the boundary-wise metrics. We extensively verify the generalization ability of polyp lesion segmentation that has similar characteristics, and our model can also yield significant improvement compared to the latest models.
PDF Abstract


 Kvasir-SEG
Kvasir-SEG
