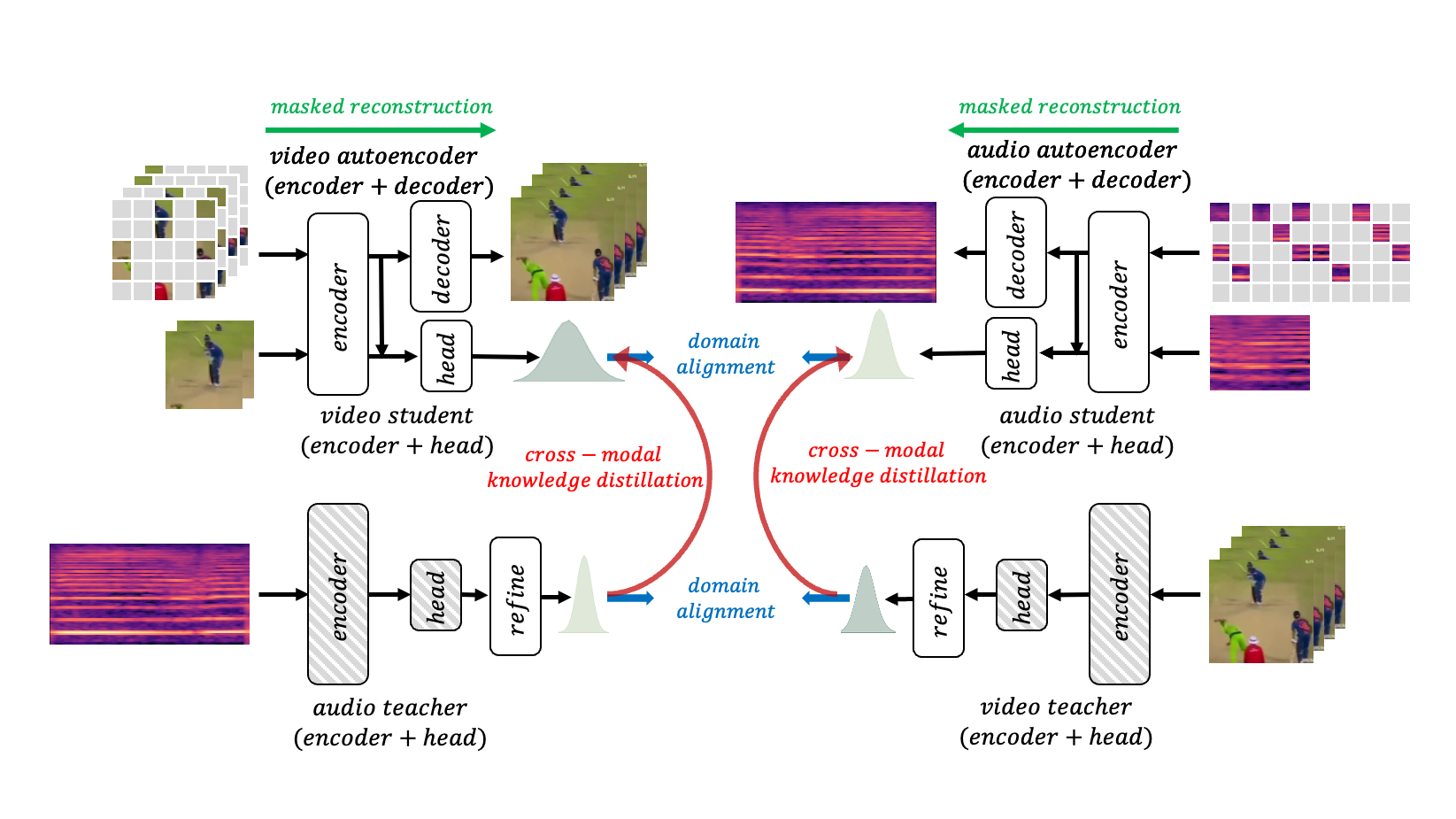
XKD: Cross-modal Knowledge Distillation with Domain Alignment for Video Representation Learning
We present XKD, a novel self-supervised framework to learn meaningful representations from unlabelled videos. XKD is trained with two pseudo objectives. First, masked data reconstruction is performed to learn modality-specific representations from audio and visual streams. Next, self-supervised cross-modal knowledge distillation is performed between the two modalities through a teacher-student setup to learn complementary information. We introduce a novel domain alignment strategy to tackle domain discrepancy between audio and visual modalities enabling effective cross-modal knowledge distillation. Additionally, to develop a general-purpose network capable of handling both audio and visual streams, modality-agnostic variants of XKD are introduced, which use the same pretrained backbone for different audio and visual tasks. Our proposed cross-modal knowledge distillation improves video action classification by $8\%$ to $14\%$ on UCF101, HMDB51, and Kinetics400. Additionally, XKD improves multimodal action classification by $5.5\%$ on Kinetics-Sound. XKD shows state-of-the-art performance in sound classification on ESC50, achieving top-1 accuracy of $96.5\%$.
PDF Abstract





 UCF101
UCF101
 Kinetics
Kinetics
 HMDB51
HMDB51
 Kinetics 400
Kinetics 400
 AudioSet
AudioSet
 ESC-50
ESC-50
 FSD50K
FSD50K

