XSkill: Cross Embodiment Skill Discovery
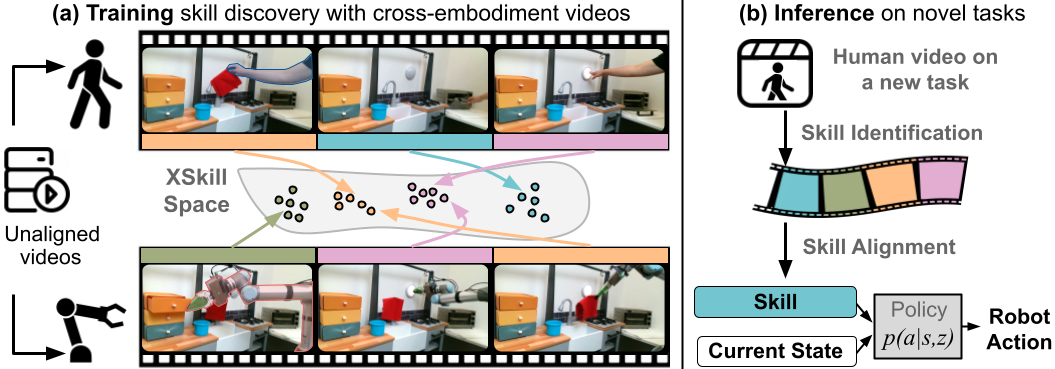
Human demonstration videos are a widely available data source for robot learning and an intuitive user interface for expressing desired behavior. However, directly extracting reusable robot manipulation skills from unstructured human videos is challenging due to the big embodiment difference and unobserved action parameters. To bridge this embodiment gap, this paper introduces XSkill, an imitation learning framework that 1) discovers a cross-embodiment representation called skill prototypes purely from unlabeled human and robot manipulation videos, 2) transfers the skill representation to robot actions using conditional diffusion policy, and finally, 3) composes the learned skill to accomplish unseen tasks specified by a human prompt video. Our experiments in simulation and real-world environments show that the discovered skill prototypes facilitate both skill transfer and composition for unseen tasks, resulting in a more general and scalable imitation learning framework. The benchmark, code, and qualitative results are on https://xskill.cs.columbia.edu/
PDF Abstract

