Your Vision-Language Model Itself Is a Strong Filter: Towards High-Quality Instruction Tuning with Data Selection
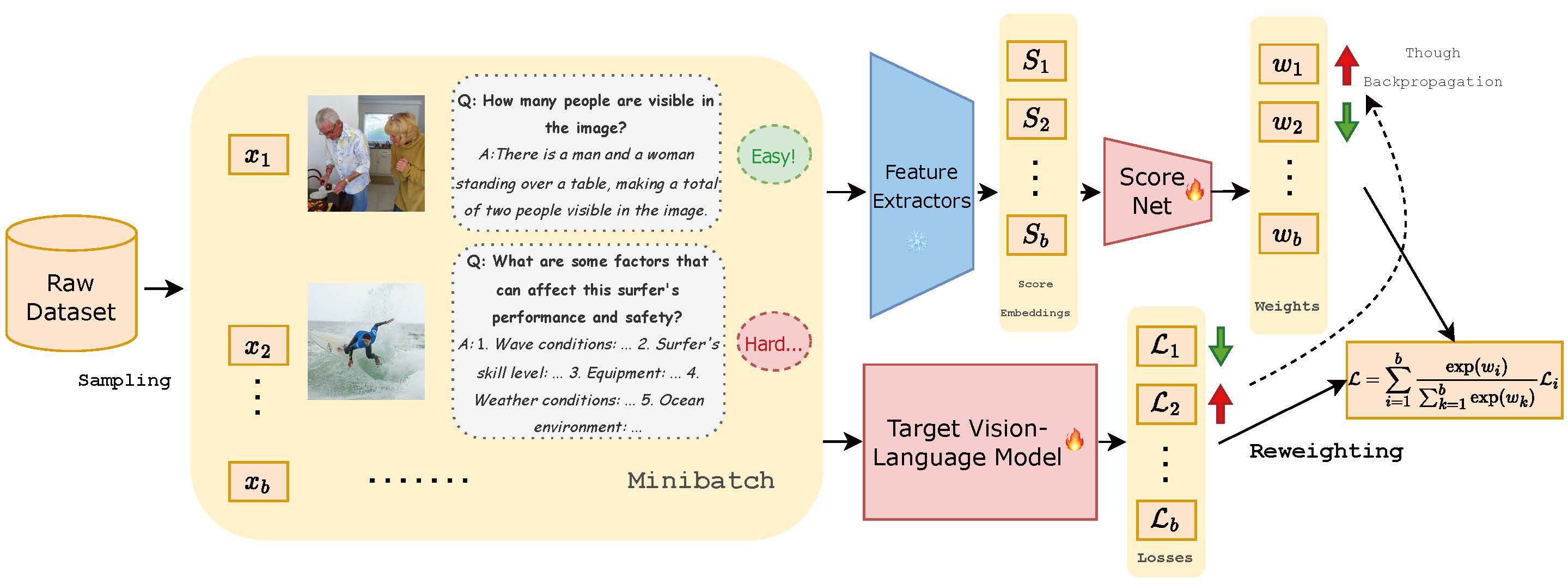
Data selection in instruction tuning emerges as a pivotal process for acquiring high-quality data and training instruction-following large language models (LLMs), but it is still a new and unexplored research area for vision-language models (VLMs). Existing data selection approaches on LLMs either rely on single unreliable scores, or use downstream tasks for selection, which is time-consuming and can lead to potential over-fitting on the chosen evaluation datasets. To address this challenge, we introduce a novel dataset selection method, Self-Filter, that utilizes the VLM itself as a filter. This approach is inspired by the observation that VLMs benefit from training with the most challenging instructions. Self-Filter operates in two stages. In the first stage, we devise a scoring network to evaluate the difficulty of training instructions, which is co-trained with the VLM. In the second stage, we use the trained score net to measure the difficulty of each instruction, select the most challenging samples, and penalize similar samples to encourage diversity. Comprehensive experiments on LLaVA and MiniGPT-4 show that Self-Filter can reach better results compared to full data settings with merely about 15% samples, and can achieve superior performance against competitive baselines.
PDF Abstract


 MS COCO
MS COCO
 OK-VQA
OK-VQA
 TextVQA
TextVQA
 VCR
VCR
 VisDial
VisDial
 ScienceQA
ScienceQA
 MMBench
MMBench
 SEED-Bench
SEED-Bench
