Zooming Slow-Mo: Fast and Accurate One-Stage Space-Time Video Super-Resolution
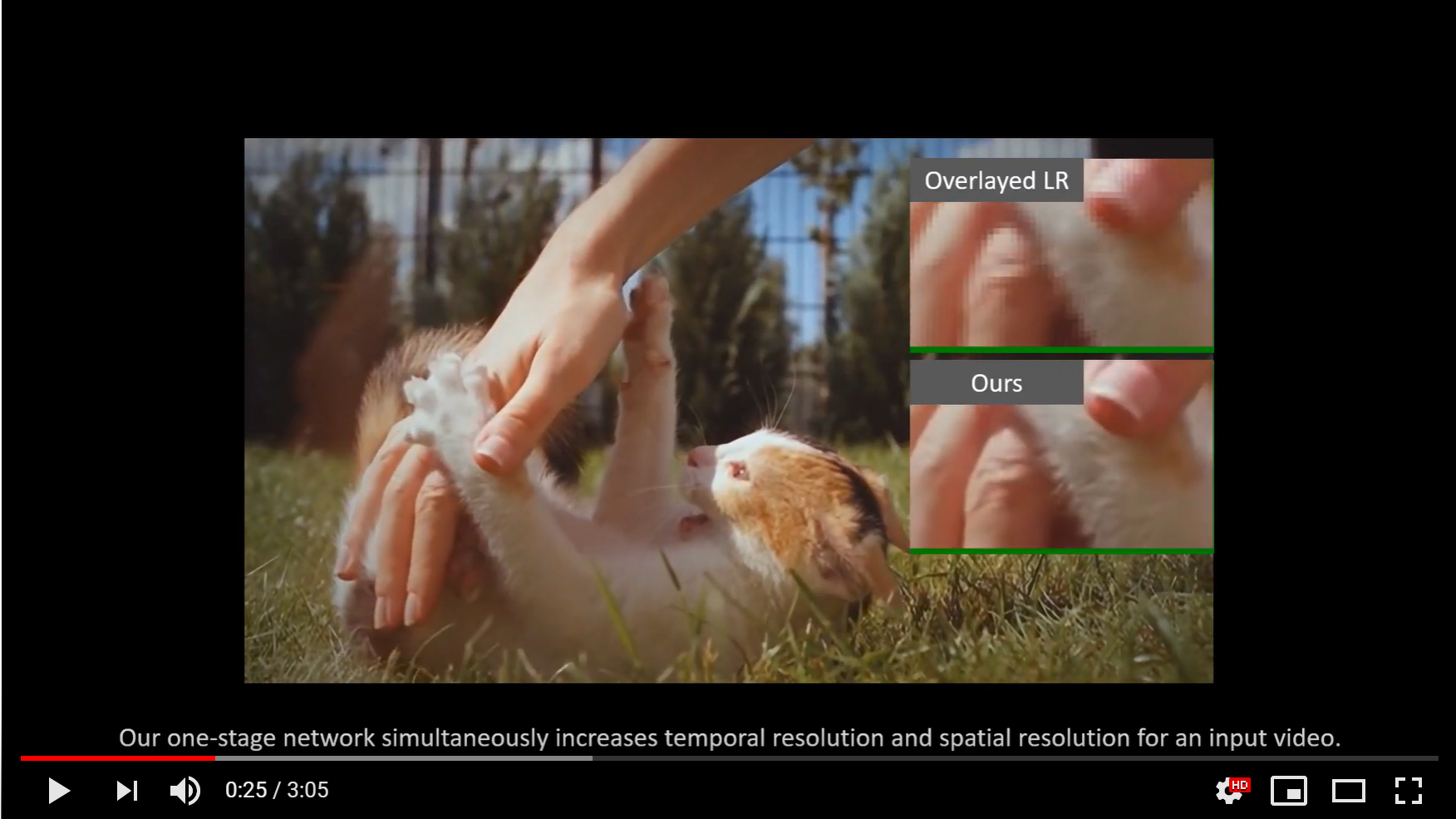
In this paper, we explore the space-time video super-resolution task, which aims to generate a high-resolution (HR) slow-motion video from a low frame rate (LFR), low-resolution (LR) video. A simple solution is to split it into two sub-tasks: video frame interpolation (VFI) and video super-resolution (VSR). However, temporal interpolation and spatial super-resolution are intra-related in this task. Two-stage methods cannot fully take advantage of the natural property. In addition, state-of-the-art VFI or VSR networks require a large frame-synthesis or reconstruction module for predicting high-quality video frames, which makes the two-stage methods have large model sizes and thus be time-consuming. To overcome the problems, we propose a one-stage space-time video super-resolution framework, which directly synthesizes an HR slow-motion video from an LFR, LR video. Rather than synthesizing missing LR video frames as VFI networks do, we firstly temporally interpolate LR frame features in missing LR video frames capturing local temporal contexts by the proposed feature temporal interpolation network. Then, we propose a deformable ConvLSTM to align and aggregate temporal information simultaneously for better leveraging global temporal contexts. Finally, a deep reconstruction network is adopted to predict HR slow-motion video frames. Extensive experiments on benchmark datasets demonstrate that the proposed method not only achieves better quantitative and qualitative performance but also is more than three times faster than recent two-stage state-of-the-art methods, e.g., DAIN+EDVR and DAIN+RBPN.
PDF Abstract CVPR 2020 PDF CVPR 2020 Abstract




