 On-Policy TD Control
On-Policy TD Control
Expected Sarsa
Expected Sarsa is like Q-learning but instead of taking the maximum over next state-action pairs, we use the expected value, taking into account how likely each action is under the current policy.
$$Q\left(S_{t}, A_{t}\right) \leftarrow Q\left(S_{t}, A_{t}\right) + \alpha\left[R_{t+1} + \gamma\sum_{a}\pi\left(a\mid{S_{t+1}}\right)Q\left(S_{t+1}, a\right) - Q\left(S_{t}, A_{t}\right)\right] $$
Except for this change to the update rule, the algorithm otherwise follows the scheme of Q-learning. It is more computationally expensive than Sarsa but it eliminates the variance due to the random selection of $A_{t+1}$.
Source: Sutton and Barto, Reinforcement Learning, 2nd Edition
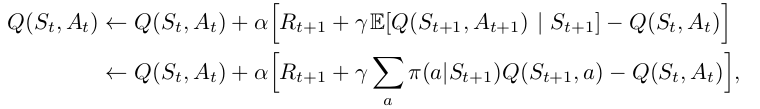
Papers
| Paper | Code | Results | Date | Stars |
|---|
Usage Over Time
Components
| Component | Type |
|
|---|---|---|
| 🤖 No Components Found | You can add them if they exist; e.g. Mask R-CNN uses RoIAlign |

