 Text-to-Speech Models
Text-to-Speech Models
FastSpeech 2
Introduced by Ren et al. in FastSpeech 2: Fast and High-Quality End-to-End Text to SpeechFastSpeech2 is a text-to-speech model that aims to improve upon FastSpeech by better solving the one-to-many mapping problem in TTS, i.e., multiple speech variations corresponding to the same text. It attempts to solve this problem by 1) directly training the model with ground-truth target instead of the simplified output from teacher, and 2) introducing more variation information of speech (e.g., pitch, energy and more accurate duration) as conditional inputs. Specifically, in FastSpeech 2, we extract duration, pitch and energy from speech waveform and directly take them as conditional inputs in training and use predicted values in inference.
The encoder converts the phoneme embedding sequence into the phoneme hidden sequence, and then the variance adaptor adds different variance information such as duration, pitch and energy into the hidden sequence, finally the mel-spectrogram decoder converts the adapted hidden sequence into mel-spectrogram sequence in parallel. FastSpeech 2 uses a feed-forward Transformer block, which is a stack of self-attention and 1D-convolution as in FastSpeech, as the basic structure for the encoder and mel-spectrogram decoder.
Source: FastSpeech 2: Fast and High-Quality End-to-End Text to Speech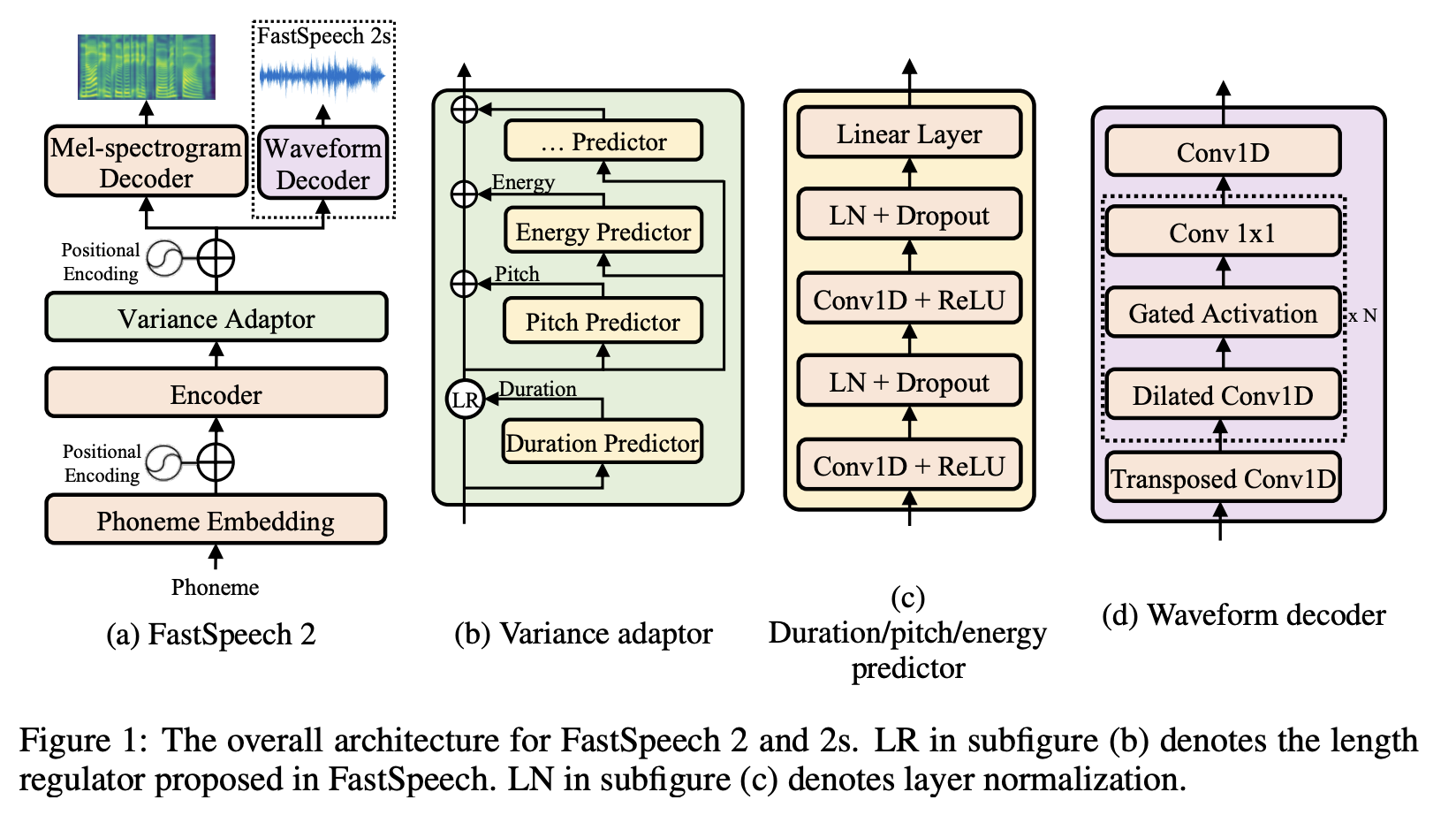
Papers
| Paper | Code | Results | Date | Stars |
|---|
Tasks
| Task | Papers | Share |
|---|---|---|
| Text-To-Speech Synthesis | 5 | 16.67% |
| Speech Synthesis | 5 | 16.67% |
| Speech-to-Speech Translation | 2 | 6.67% |
| Translation | 2 | 6.67% |
| Natural Language Understanding | 1 | 3.33% |
| Speech Recognition | 1 | 3.33% |
| Spoken Language Understanding | 1 | 3.33% |
| Cross-Lingual Transfer | 1 | 3.33% |
| Speech-to-Text Translation | 1 | 3.33% |
 Dropout
Dropout
 Layer Normalization
Layer Normalization
 Multi-Head Attention
Multi-Head Attention
 ReLU
ReLU
 Residual Connection
Residual Connection
 Scaled Dot-Product Attention
Scaled Dot-Product Attention
