 3D Representations
3D Representations
Language-driven Scene Synthesis using Multi-conditional Diffusion Model
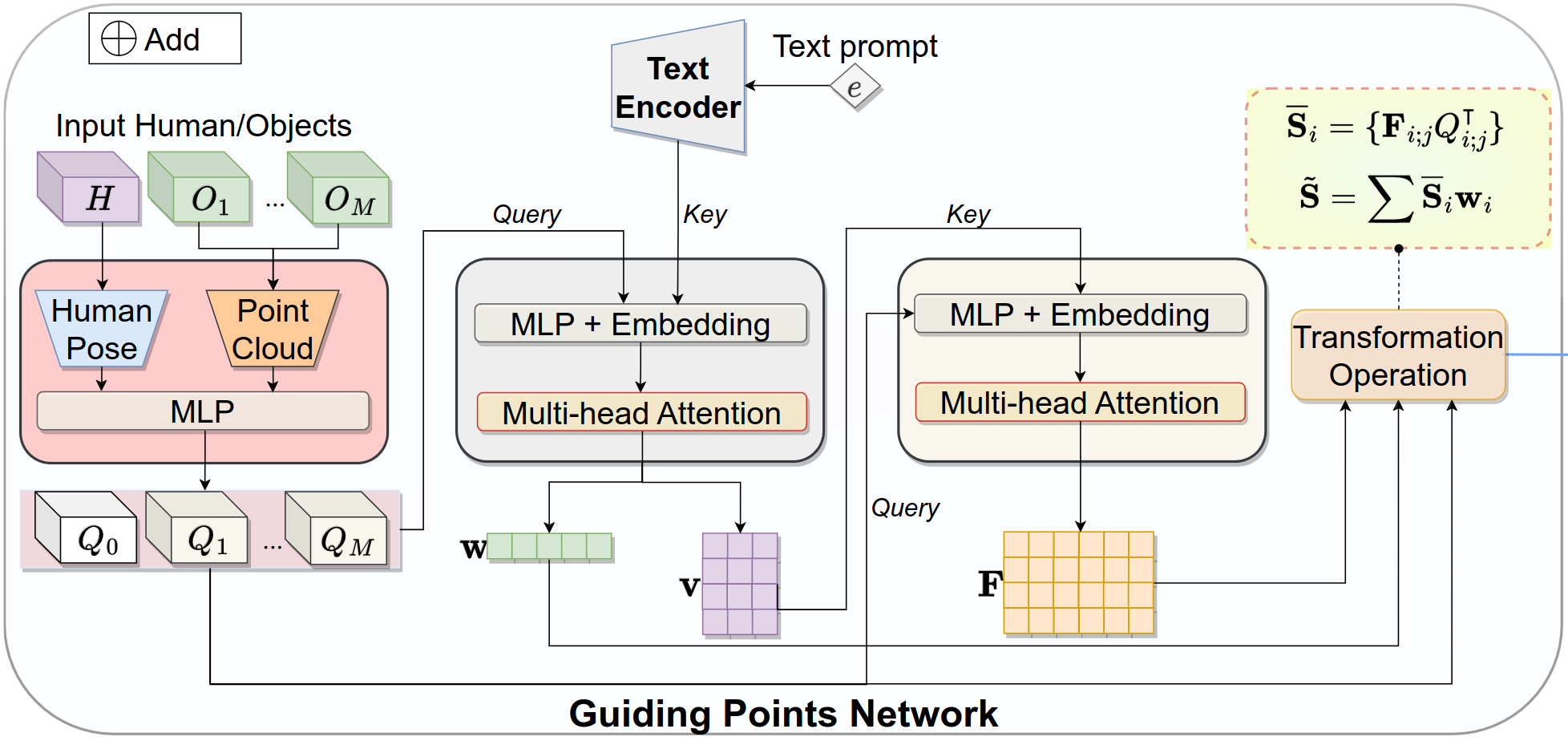
Our main contribution is the Guiding Points Network, where we integrate all information from the conditions to generate guiding points. By applying transformation matrices to scene entities (human/objects) with attention weighting, we can forecast the spanning of the target object.
Papers
| Paper | Code | Results | Date | Stars |
|---|
Tasks
| Task | Papers | Share |
|---|---|---|
| knowledge editing | 1 | 16.67% |
| Language Modelling | 1 | 16.67% |
| Large Language Model | 1 | 16.67% |
| Sentence | 1 | 16.67% |
| 3D scene Editing | 1 | 16.67% |
| Indoor Scene Synthesis | 1 | 16.67% |
Usage Over Time
Components
| Component | Type |
|
|---|---|---|
 CLIP
CLIP
|
Image Representations | |
 DGCNN
DGCNN
|
Graph Models | |
|
Latent Diffusion Model
|
Dimensionality Reduction | |
 PointNet
PointNet
|
3D Representations |
