 Transformers
Transformers
Transformer in Transformer
Introduced by Han et al. in Transformer in TransformerTransformer is a type of self-attention-based neural networks originally applied for NLP tasks. Recently, pure transformer-based models are proposed to solve computer vision problems. These visual transformers usually view an image as a sequence of patches while they ignore the intrinsic structure information inside each patch. In this paper, we propose a novel Transformer-iN-Transformer (TNT) model for modeling both patch-level and pixel-level representation. In each TNT block, an outer transformer block is utilized to process patch embeddings, and an inner transformer block extracts local features from pixel embeddings. The pixel-level feature is projected to the space of patch embedding by a linear transformation layer and then added into the patch. By stacking the TNT blocks, we build the TNT model for image recognition.
Image source: Han et al.
Source: Transformer in Transformer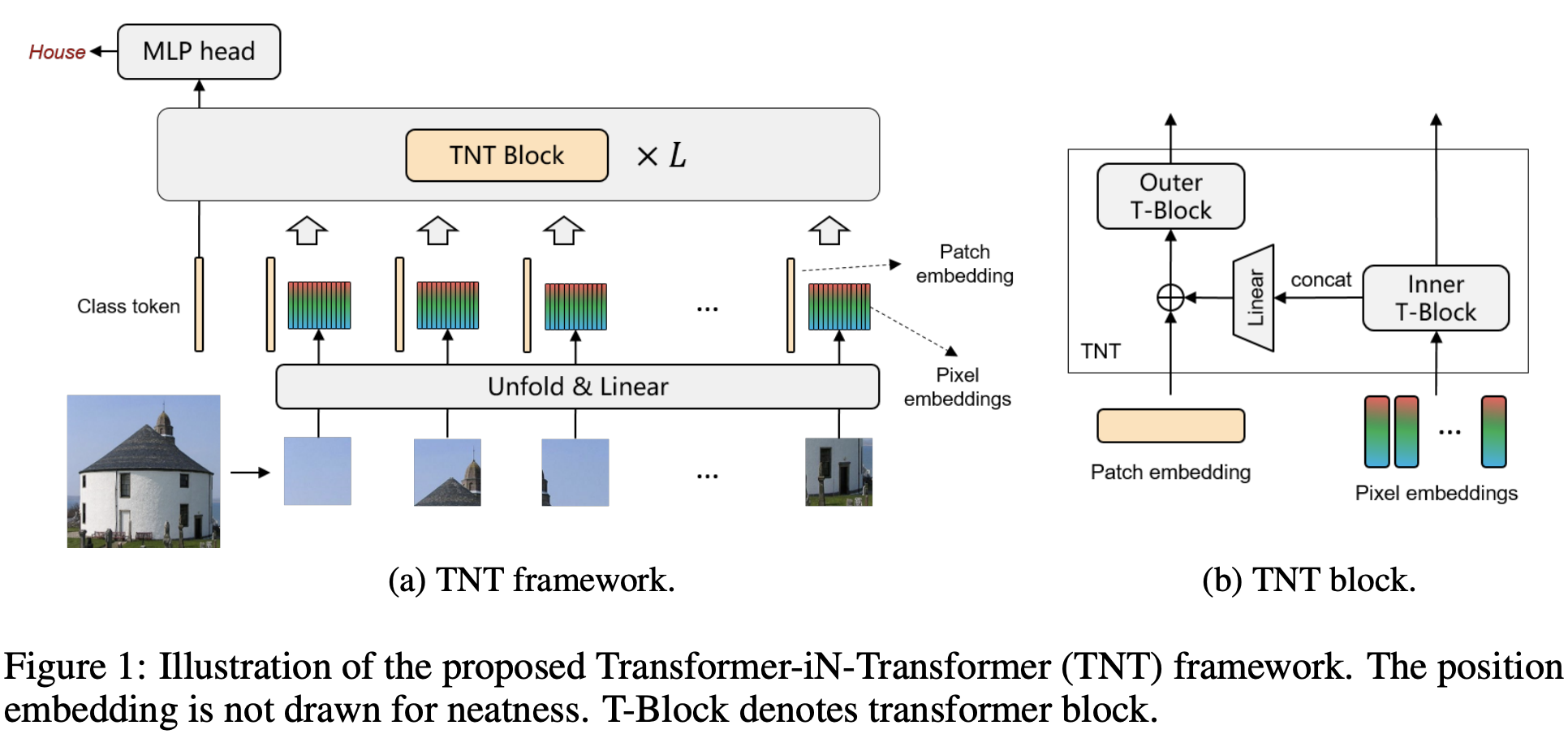
Papers
| Paper | Code | Results | Date | Stars |
|---|
Tasks
| Task | Papers | Share |
|---|---|---|
| Image Classification | 2 | 40.00% |
| Sentence | 2 | 40.00% |
| Fine-Grained Image Classification | 1 | 20.00% |
Usage Over Time
Components
| Component | Type |
|
|---|---|---|
| 🤖 No Components Found | You can add them if they exist; e.g. Mask R-CNN uses RoIAlign |


