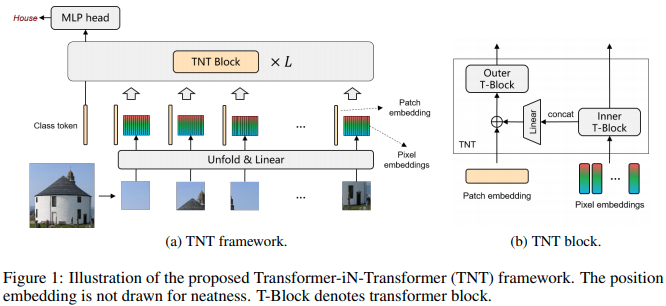
Transformer in Transformer
Transformer is a new kind of neural architecture which encodes the input data as powerful features via the attention mechanism. Basically, the visual transformers first divide the input images into several local patches and then calculate both representations and their relationship. Since natural images are of high complexity with abundant detail and color information, the granularity of the patch dividing is not fine enough for excavating features of objects in different scales and locations. In this paper, we point out that the attention inside these local patches are also essential for building visual transformers with high performance and we explore a new architecture, namely, Transformer iN Transformer (TNT). Specifically, we regard the local patches (e.g., 16$\times$16) as "visual sentences" and present to further divide them into smaller patches (e.g., 4$\times$4) as "visual words". The attention of each word will be calculated with other words in the given visual sentence with negligible computational costs. Features of both words and sentences will be aggregated to enhance the representation ability. Experiments on several benchmarks demonstrate the effectiveness of the proposed TNT architecture, e.g., we achieve an 81.5% top-1 accuracy on the ImageNet, which is about 1.7% higher than that of the state-of-the-art visual transformer with similar computational cost. The PyTorch code is available at https://github.com/huawei-noah/CV-Backbones, and the MindSpore code is available at https://gitee.com/mindspore/models/tree/master/research/cv/TNT.
PDF Abstract NeurIPS 2021 PDF NeurIPS 2021 Abstract



 Colab
Colab




 CIFAR-10
CIFAR-10
 ImageNet
ImageNet
 MS COCO
MS COCO
 CIFAR-100
CIFAR-100
 Oxford 102 Flower
Oxford 102 Flower
 ADE20K
ADE20K
 iNaturalist
iNaturalist
 Oxford-IIIT Pet Dataset
Oxford-IIIT Pet Dataset

