Vision and Language Pre-Trained Models
Computer Vision • 31 methods
Involves models that adapt pre-training to the field of Vision-and-Language (V-L) learning and improve the performance on downstream tasks like visual question answering and visual captioning.
According to Du et al. (2022), information coming from the different modalities can be encoded in three ways: fusion encoder, dual encoder, and a combination of both.
References:
Methods
| Method | Year | Papers |
|---|---|---|
| 2021 | 2282 | |
| 2021 | 1650 | |
| 2022 | 51 | |
| 2019 | 39 | |
| 2019 | 30 | |
| 2020 | 23 | |
| 2019 | 22 | |
| 2022 | 21 | |
| 2021 | 18 | |
| 2021 | 14 | |
| 2021 | 9 | |
| 2021 | 6 | |
| 2021 | 5 | |
| 2000 | 5 | |
| 2019 | 4 | |
| 2020 | 4 | |
| 2021 | 4 | |
| 2021 | 4 | |
| 2021 | 3 | |
| 2021 | 3 | |
| 2022 | 3 | |
| 2023 | 3 | |
| 2020 | 2 | |
| 2000 | 2 | |
| 2022 | 2 | |
| 2020 | 1 | |
| 2019 | 1 | |
| 2020 | 1 | |
| 2021 | 1 | |
| 2022 | 1 |
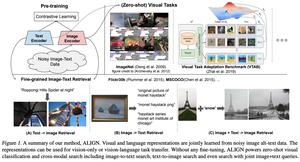 ALIGN
ALIGN
 CLIP
CLIP
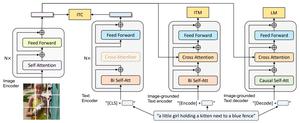 BLIP
BLIP
 LXMERT
LXMERT
 ViLBERT
ViLBERT
 OSCAR
OSCAR
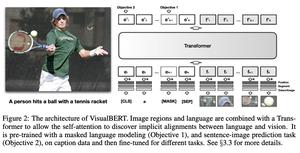 VisualBERT
VisualBERT
 OFA
OFA
 ViLT
ViLT
 ALBEF
ALBEF
 FLAVA
FLAVA
 Florence
Florence
 Visual Parsing
Visual Parsing
 InternVideo
InternVideo
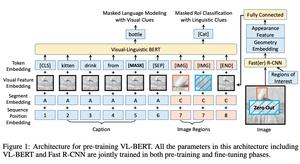 VL-BERT
VL-BERT
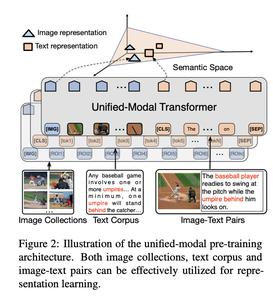 UNIMO
UNIMO
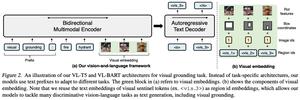 VL-T5
VL-T5
 WenLan
WenLan
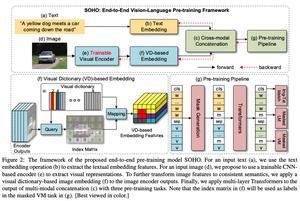 SOHO
SOHO
 SimVLM
SimVLM
 PLIP
PLIP
 Pixel-BERT
Pixel-BERT
 Kaleido-BERT
Kaleido-BERT
 InterBERT
InterBERT
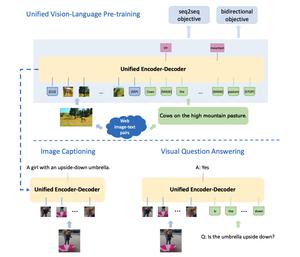 Unified VLP
Unified VLP
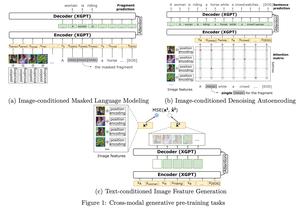 XGPT
XGPT
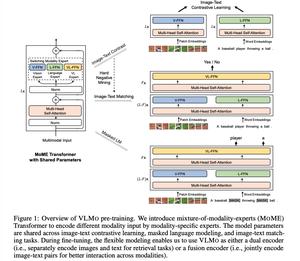 VLMo
VLMo
 OneR
OneR
