Papers with Code Newsletter #12
Welcome to the 12th issue of the Papers with Code newsletter. In this edition, we cover:
- a summary of the latest works in deep learning for tabular data problems
- an approach for parameter-efficient representations of large knowledge graphs
- findings on how to better train Vision Transformers
- a collection of the top trending papers of June 2021
- ... and much more
Trending Papers with Code 📄
Deep Learning for Tabular Data
Over the past few years, deep learning has been successfully applied to a variety of problems involving different kinds of data such as image and textual information. The rise of Transformers have produced effective and efficient deep learning architectures applied to a variety of problems in computer vision and NLP such as image classification and question answering, respectively.
Most recently, these models have made it to other paradigms such as reinforcement learning. However, deep learning models have lagged in performance on tabular data problems where other types of algorithms like random forests and gradient boosted decision trees are notoriously more effective. Recently, many works have proposed efforts using deep learning architectures to more effectively work on tabular data for a variety of tasks. However, different benchmarks are used, models are not compared directly, making it difficult to identify the best models for practitioners.
Below we highlight a few of these recent works proposing deep learning based architectures for tabular data problems:
Revisiting Deep Learning Models for Tabular data

Overview of the FT-Transformer architecture. (a) Feature tokenizer transforms features to tokens. (b) The tokens are then processed by the Transformer module.
Although recent reported results have shown that deep learning architectures outperform "shallow" models like Gradient Boosted Decision Trees (GBDTs), it is unclear if this is happening universally. Additionally, in a lot of cases where experimentation exists there is no direct comparison and different benchmarks are used. A recent paper by Gorishniy et al. (2021) provides a thorough review of recent deep learning architectures for tabular data. It also proposes a simple deep learning architecture, called FT-Transformer, to work on tabular data. FT-Transformer transforms features to tokens which are then processed by a transformer module.
Main findings: This work reports that the choice between both family of models (GBDT and DL models) is heavily dependent on data and there is still no universally superior solution. In addition, a simple ResNet-like architecture provides an effective baseline, which outperforms most of the architectures in the DL literature. The authors also propose an adaptation of the Transformer architecture (see figure above) that works with tabular data which provides a new strong baseline that reduces the gap between GBDT and DL models on datasets where GBDTs dominate.
Improved Neural Networks for Tabular Data

The SAINT architecture with pre-training and training pipelines. Figure source: Somepalli et al. (2021)
Somepalli et al. (2021) recently proposed a hybrid deep learning approach, called SAINT, to address tabular data problems. SAINT performs attention over both rows and columns, including an enhanced embedding method. SAINT projects all features into a combined dense vector space. The projected values are passed as tokens into a transformer encoder where "self attention" and "intersample attention" are applied. Intersample attention enhances classification by relating a row to other rows in the table. In addition, this study also leverages contrastive self-supervised pre-training method to use when labels are scarce and boost performance for semi-supervised problems. As shown in the reported results, SAINT consistently outperforms previous deep learning methods and gradient boosting methods like XGBoost and CatBoost on a variety of benchmark tasks.
Recent Papers in Deep Learning for Tabular Data
The following list consists of some other recent works proposing deep learning architectures for tabular data problems:
📄 TaBERT - Yin et al. (2021)
📄 TABBIE - Iida et al. (2021)
📄 TAPAS - Herzig et al. (2020)
📄 TabTransformer - Huang et al. (2020)
📄 VIME - Yoon et al. (2020)
📄 Neural Oblivious Decision Ensembles - Povov et al. (2020)
📄 Gradient Boosting Neural Networks - Badirli et al. (2020)
📄 DCN V2 - Wang et al. (2020)
📄 TabNet - Arik and Pfister (2019)
📄 AutoInt - Song et al. (2018)
Compositional and Parameter-Efficient Representations of Large Knowledge Graphs

NodePiece tokenization strategy: Given three anchors a1, a2, a3, a target node can be tokenized into a hash of top-k closest anchors, their distances to the target node, and the relational context of outgoing relations from the target node. Figure source: Galkin et al. (2021)
Current representation learning techniques for real-world knowledge graphs (KGs) incur high computational costs due to the linear growth of memory consumption needed for storing the embedding matrix, i.e., each entity is mapped to a unique embedding vector. Borrowing inspiration from subword tokenization used in NLP, Galkin et al. (2021) propose a more parameter-efficient node embedding strategy, called NodePiece, with possibly sublinear memory requirements.
What it is: NodePiece is an anchor-based approach to learn a fixed-sized entity vocabulary. A vocabulary of sub-entity units is constructed from anchor nodes in a graph with known relation types. The fixed-sized vocabulary is used to bootstrap an encoding and embedding for any entity, including those unseen during training. Results show that a fixed-size NodePiece vocabulary paired with a simple encoder performs competitively in node classification, and other graph related tasks like link prediction. One of the benefits of using NodePiece is that it can perform well on these tasks while retaining less than 10% of explicit nodes in a graph as anchors and often having 10x fewer parameters.
How to Train Vision Transformers?
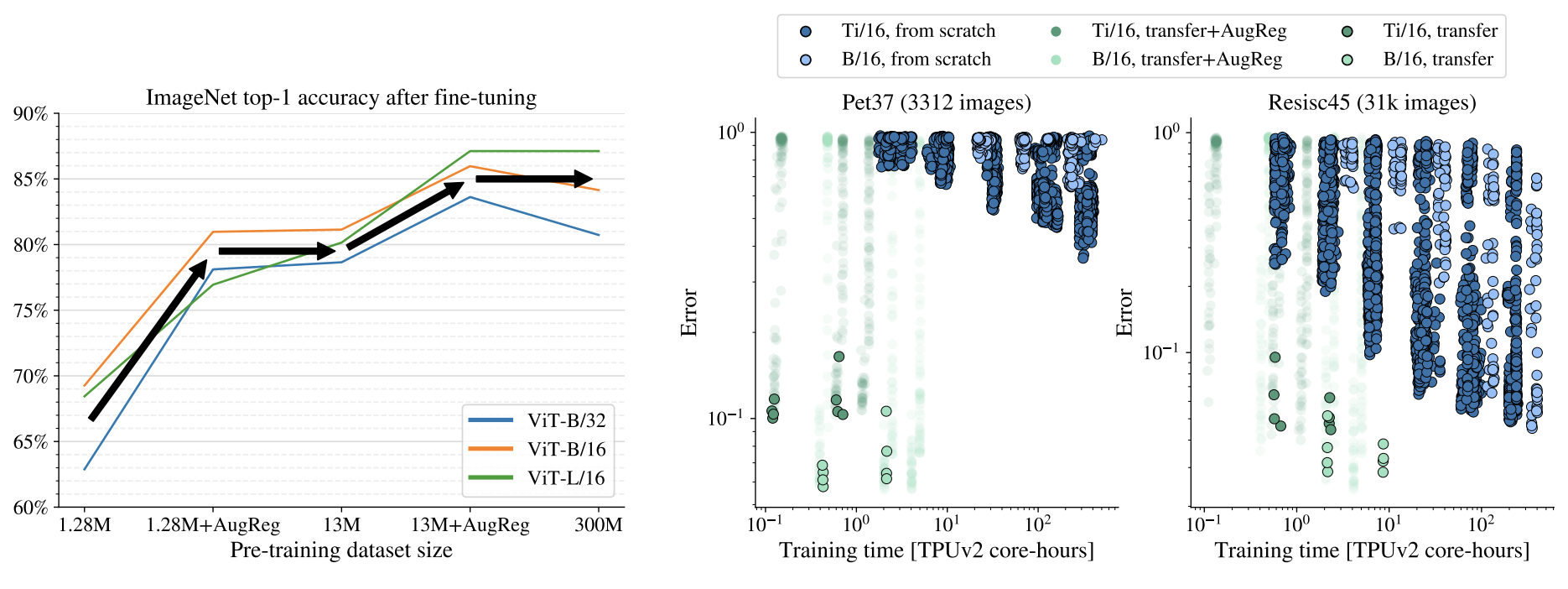
(Left) Shows that similar gains can be attained with regularization and augmentation as increasing the dataset size by an order of magnitude. (Right) Shows test error obtained when using small and mid-sized datasets given two scenarios: training from scratch (blue circles) or fine-tuning a model pre-trained on a large dataset (green circles). Figure source: Steiner et al. (2021)
Vision Transformers (ViT) have shown feasible for computer vision and have attained good performance on tasks such as image classification and semantic image segmentation. However, results on smaller training datasets have shown that the weaker inductive bias of these models (compared to CNNs) cause them to be more reliant on data augmentation or model regularization ("AugReg" for short). Steiner et al. (2021) recently proposed a systematic empirical study to better understand the interplay between amount of training data, AugReg, model size, and compute budget.
Main findings: Results show that models using a combination of AugReg and increased compute can attain similar performance as models trained on an order of magnitude more training data. For instance, ViT models of various sizes, trained on ImageNet-21k, match or outperform counterparts trained on a larger dataset (JFT-300M). The authors report that for small and mid-sized datasets it is hard to achieve a test error that can be attained by fine-tuning a model pre-trained on a large dataset like ImageNet-21k. The figure above also shows that it is possible to find a good solution with a few trials (bordered green dots) and AugReg is not helpful when transferring pre-trained models (borderless green dots).
Top 10 Trending Papers of June 2021 🏆
As with every end of the month, we share the top 10 trending papers of June 2021:
📄 GANs N' Roses - Chong and Forsyth (2021)
📄 Decision Transformer - Chen et al. (2021)
📄 Scaling Vision Transformers - Zhai et al. (2021)
📄 Dynamic Head - Dai et al. (2021)
📄 Vision Outlooker for Visual Recognition - Yuan et al. (2021)
📄 DouZero - Zha et al. (2021)
📄 SimSwap - Chen et al. (2021)
📄 Plan2Scene - Vidanapathirana et al. (2021)
📄 Cross-Covariance Image Transformers - El-Nouby et al. (2021)
📄 Towards Total Recall in Industrial Anomaly Detection - Roth et al. (2021)
Trending Libraries and Datasets 🛠
Trending datasets
ONCE (One millioN sCenEs) - A dataset for 3D object detection in the autonomous driving scenario. The ONCE dataset consists of 1 million LiDAR scenes and 7 million corresponding camera images. The data is selected from 144 driving hours.
AIT-QA - A dataset for table question answering which is specific to the airline industry.
UDIS-D - A large image dataset for image stitching or image registration. It contains different overlap rates, varying degrees of parallax, and variable scenes such as indoor, outdoor, night, dark, snow, and zooming.
Trending libraries/tools
PyKale - A Python library for knowledge-aware machine learning on graphs, text, and videos to enable and accelerate interdisciplinary research.
DeepLab2 - A TensorFlow library for deep labeling which provide TensorFlow codebase for general dense pixel prediction problems.
RLCard - A toolkit for reinforcement learning research in card games.
Community Highlights ✍️
We would like to thank:
- @zeliu98 for contributing to several benchmarks, including the addition of several tags to the Semantic Segmentation on ADE20K val benchmark benchmarks.
- @Rybolos for several contributions to Papers with Code, including addition of results to RussianSuperGLUE.
- @shakedbr for contributing to Methods, including the entry for Graph Attention Networks v2.
- @abdoelsayed2016 for contributing to Datasets, including the addition of the TNCR dataset for table detection.
- @paulchhuang for contributing to Datasets, including the addition of AGORA dataset (a synthetic human dataset with high realism).
Special thanks to @anchit, @stevewong, @ravikiran, @ZiaoGuo, @jin-s13, and the hundreds of other contributors for their contributions to Papers with Code.
---
We would be happy to hear your thoughts and suggestions on the newsletter. Please reply to elvis@paperswithcode.com.
