A Multi-dimensional Deep Structured State Space Approach to Speech Enhancement Using Small-footprint Models
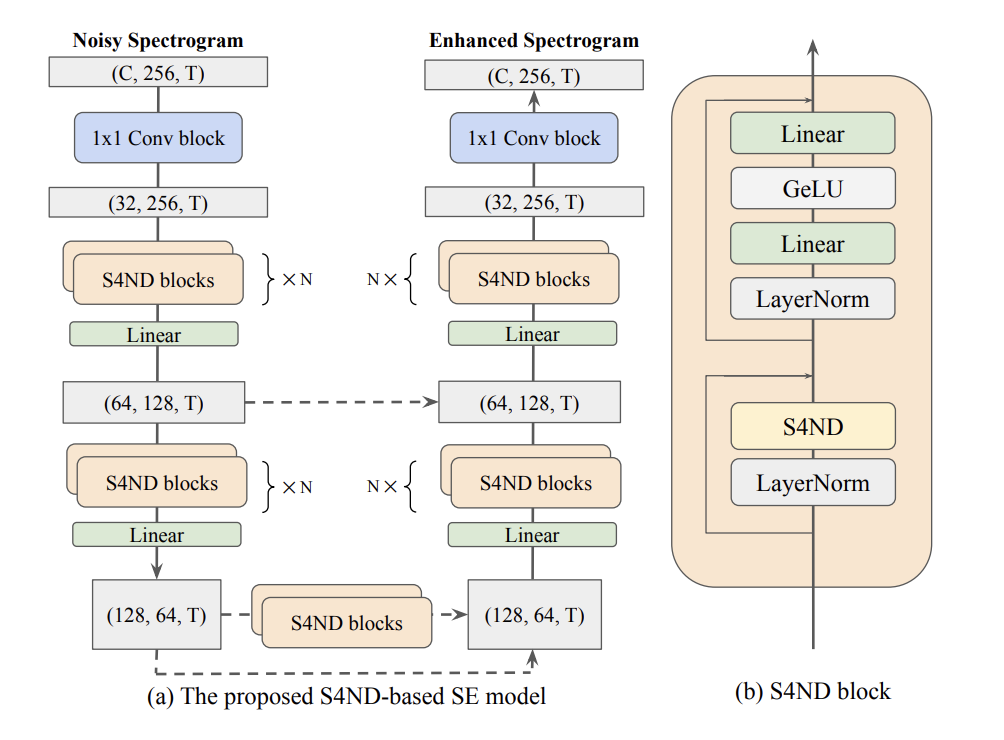
We propose a multi-dimensional structured state space (S4) approach to speech enhancement. To better capture the spectral dependencies across the frequency axis, we focus on modifying the multi-dimensional S4 layer with whitening transformation to build new small-footprint models that also achieve good performance. We explore several S4-based deep architectures in time (T) and time-frequency (TF) domains. The 2-D S4 layer can be considered a particular convolutional layer with an infinite receptive field although it utilizes fewer parameters than a conventional convolutional layer. Evaluated on the VoiceBank-DEMAND data set, when compared with the conventional U-net model based on convolutional layers, the proposed TF-domain S4-based model is 78.6% smaller in size, yet it still achieves competitive results with a PESQ score of 3.15 with data augmentation. By increasing the model size, we can even reach a PESQ score of 3.18.
PDF Abstract


