A Semi-Supervised Data Augmentation Approach using 3D Graphical Engines
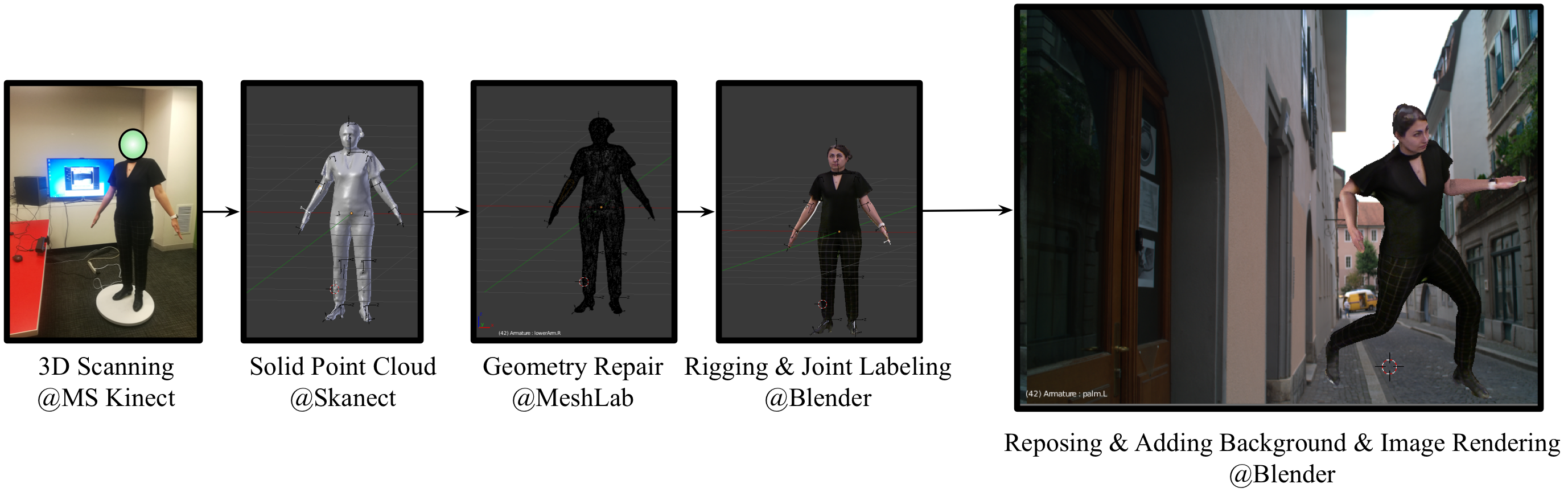
Deep learning approaches have been rapidly adopted across a wide range of fields because of their accuracy and flexibility, but require large labeled training datasets. This presents a fundamental problem for applications with limited, expensive, or private data (i.e. small data), such as human pose and behavior estimation/tracking which could be highly personalized. In this paper, we present a semi-supervised data augmentation approach that can synthesize large scale labeled training datasets using 3D graphical engines based on a physically-valid low dimensional pose descriptor. To evaluate the performance of our synthesized datasets in training deep learning-based models, we generated a large synthetic human pose dataset, called ScanAva using 3D scans of only 7 individuals based on our proposed augmentation approach. A state-of-the-art human pose estimation deep learning model then was trained from scratch using our ScanAva dataset and could achieve the pose estimation accuracy of 91.2% at PCK0.5 criteria after applying an efficient domain adaptation on the synthetic images, in which its pose estimation accuracy was comparable to the same model trained on large scale pose data from real humans such as MPII dataset and much higher than the model trained on other synthetic human dataset such as SURREAL.
PDF Abstract



 LSUN
LSUN
 MPII
MPII
 3D Chairs
3D Chairs
 SURREAL
SURREAL
