A Transductive Approach for Video Object Segmentation
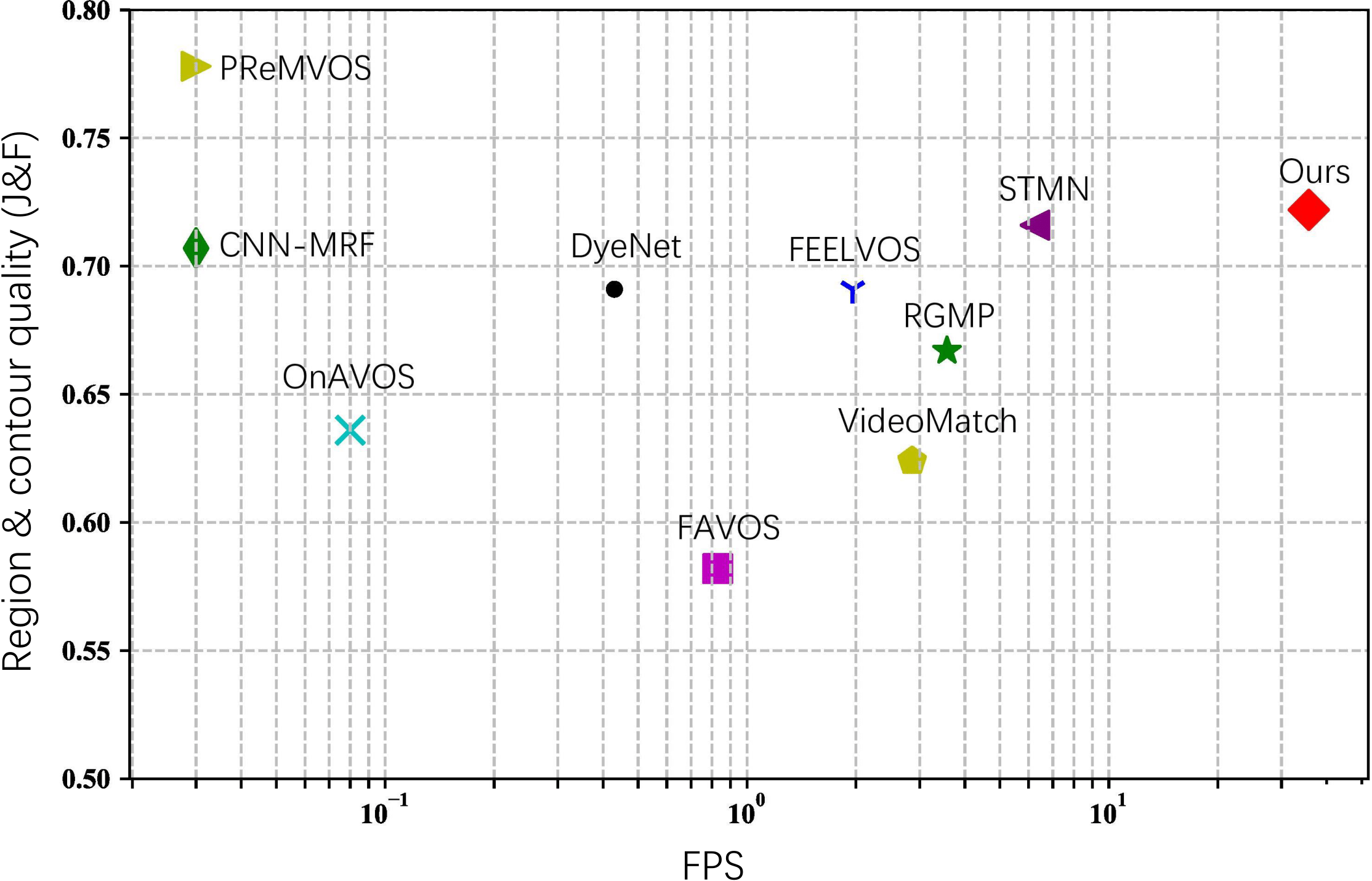
Semi-supervised video object segmentation aims to separate a target object from a video sequence, given the mask in the first frame. Most of current prevailing methods utilize information from additional modules trained in other domains like optical flow and instance segmentation, and as a result they do not compete with other methods on common ground. To address this issue, we propose a simple yet strong transductive method, in which additional modules, datasets, and dedicated architectural designs are not needed. Our method takes a label propagation approach where pixel labels are passed forward based on feature similarity in an embedding space. Different from other propagation methods, ours diffuses temporal information in a holistic manner which take accounts of long-term object appearance. In addition, our method requires few additional computational overhead, and runs at a fast $\sim$37 fps speed. Our single model with a vanilla ResNet50 backbone achieves an overall score of 72.3 on the DAVIS 2017 validation set and 63.1 on the test set. This simple yet high performing and efficient method can serve as a solid baseline that facilitates future research. Code and models are available at \url{https://github.com/microsoft/transductive-vos.pytorch}.
PDF Abstract CVPR 2020 PDF CVPR 2020 Abstract






 DAVIS
DAVIS
 DAVIS 2017
DAVIS 2017
 YouTube-VOS 2018
YouTube-VOS 2018
 Referring Expressions for DAVIS 2016 & 2017
Referring Expressions for DAVIS 2016 & 2017

