AA-RMVSNet: Adaptive Aggregation Recurrent Multi-view Stereo Network
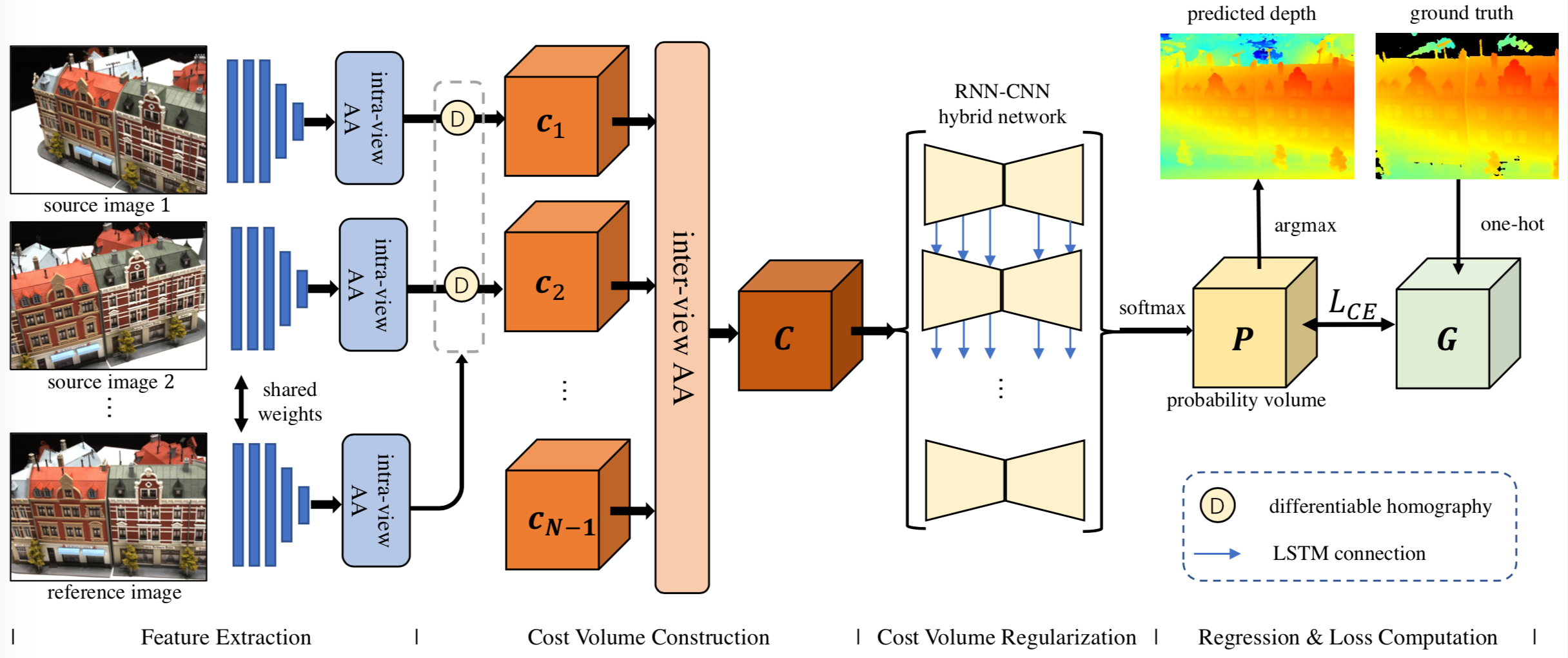
In this paper, we present a novel recurrent multi-view stereo network based on long short-term memory (LSTM) with adaptive aggregation, namely AA-RMVSNet. We firstly introduce an intra-view aggregation module to adaptively extract image features by using context-aware convolution and multi-scale aggregation, which efficiently improves the performance on challenging regions, such as thin objects and large low-textured surfaces. To overcome the difficulty of varying occlusion in complex scenes, we propose an inter-view cost volume aggregation module for adaptive pixel-wise view aggregation, which is able to preserve better-matched pairs among all views. The two proposed adaptive aggregation modules are lightweight, effective and complementary regarding improving the accuracy and completeness of 3D reconstruction. Instead of conventional 3D CNNs, we utilize a hybrid network with recurrent structure for cost volume regularization, which allows high-resolution reconstruction and finer hypothetical plane sweep. The proposed network is trained end-to-end and achieves excellent performance on various datasets. It ranks $1^{st}$ among all submissions on Tanks and Temples benchmark and achieves competitive results on DTU dataset, which exhibits strong generalizability and robustness. Implementation of our method is available at https://github.com/QT-Zhu/AA-RMVSNet.
PDF Abstract ICCV 2021 PDF ICCV 2021 AbstractCode



Datasets
 DTU
DTU
 Tanks and Temples
Tanks and Temples
Results from the Paper
 Ranked #10 on
Point Clouds
on Tanks and Temples
(Mean F1 (Intermediate) metric)
Ranked #10 on
Point Clouds
on Tanks and Temples
(Mean F1 (Intermediate) metric)
