Align and Prompt: Video-and-Language Pre-training with Entity Prompts
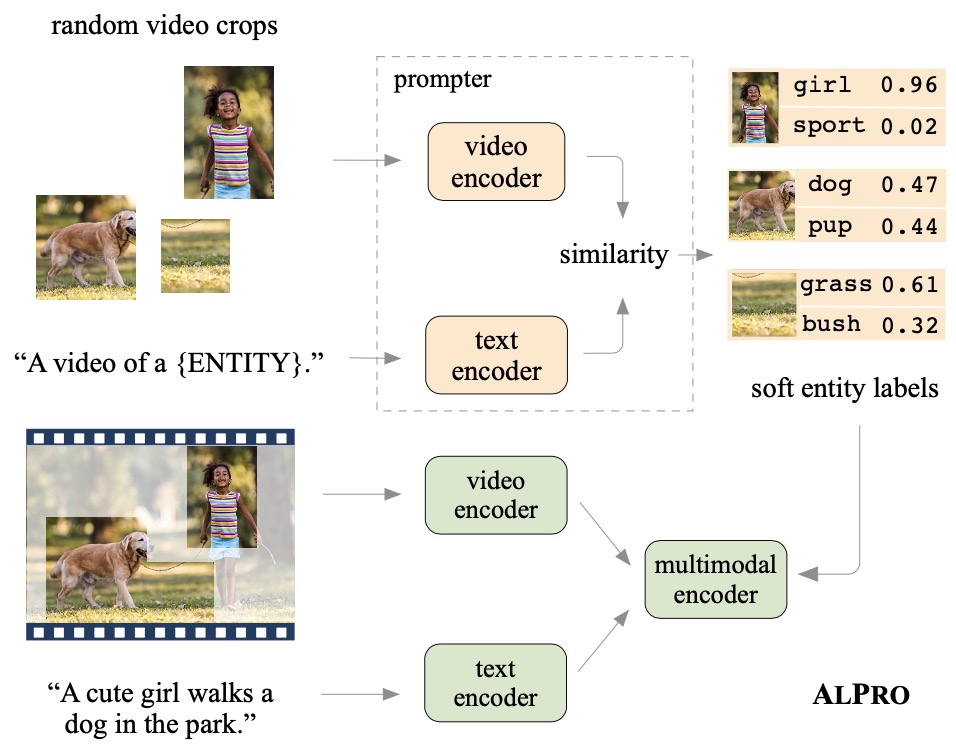
Video-and-language pre-training has shown promising improvements on various downstream tasks. Most previous methods capture cross-modal interactions with a transformer-based multimodal encoder, not fully addressing the misalignment between unimodal video and text features. Besides, learning fine-grained visual-language alignment usually requires off-the-shelf object detectors to provide object information, which is bottlenecked by the detector's limited vocabulary and expensive computation cost. We propose Align and Prompt: an efficient and effective video-and-language pre-training framework with better cross-modal alignment. First, we introduce a video-text contrastive (VTC) loss to align unimodal video-text features at the instance level, which eases the modeling of cross-modal interactions. Then, we propose a new visually-grounded pre-training task, prompting entity modeling (PEM), which aims to learn fine-grained region-entity alignment. To achieve this, we first introduce an entity prompter module, which is trained with VTC to produce the similarity between a video crop and text prompts instantiated with entity names. The PEM task then asks the model to predict the entity pseudo-labels (i.e~normalized similarity scores) for randomly-selected video crops. The resulting pre-trained model achieves state-of-the-art performance on both text-video retrieval and videoQA, outperforming prior work by a substantial margin. Our code and pre-trained models are available at https://github.com/salesforce/ALPRO.
PDF Abstract CVPR 2022 PDF CVPR 2022 AbstractCode



 MS COCO
MS COCO
 MSR-VTT
MSR-VTT
 MSVD
MSVD
 HowTo100M
HowTo100M
 DiDeMo
DiDeMo
 WebVid
WebVid

| Task | Dataset | Model | Metric Name | Metric Value | Global Rank | Uses Extra Training Data |
Benchmark |
|---|---|---|---|---|---|---|---|
| Zero-Shot Video Retrieval | DiDeMo | ALPRO | text-to-video R@1 | 23.8 | # 19 | ||
| text-to-video R@5 | 47.3 | # 21 | |||||
| text-to-video R@10 | 57.9 | # 23 | |||||
| text-to-video Median Rank | 6 | # 6 | |||||
| Video Retrieval | DiDeMo | ALPRO | text-to-video R@1 | 35.9 | # 34 | ||
| text-to-video R@5 | 67.5 | # 32 | |||||
| text-to-video R@10 | 78.8 | # 31 | |||||
| text-to-video Median Rank | 3 | # 17 | |||||
| Zero-Shot Video Retrieval | MSR-VTT | ALPRO | text-to-video R@1 | 24.1 | # 25 | ||
| text-to-video R@5 | 44.7 | # 25 | |||||
| text-to-video R@10 | 55.4 | # 25 | |||||
| text-to-video Median Rank | 8 | # 8 | |||||
| Visual Question Answering (VQA) | MSRVTT-QA | ALPRO | Accuracy | 0.421 | # 20 | ||
| Visual Question Answering (VQA) | MSVD-QA | ALPRO | Accuracy | 0.459 | # 27 |
