An Open-source Benchmark of Deep Learning Models for Audio-visual Apparent and Self-reported Personality Recognition
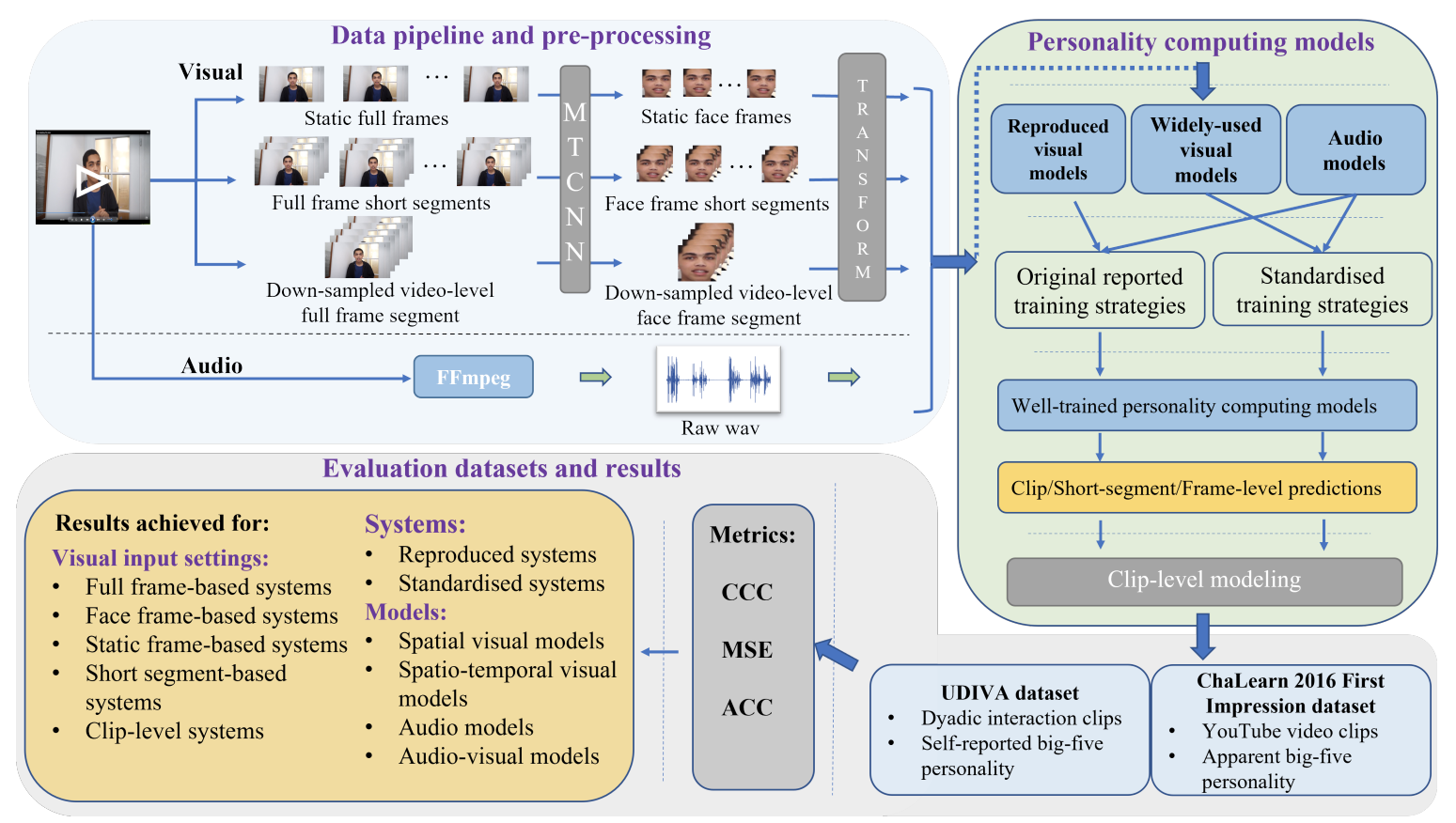
Personality determines a wide variety of human daily and working behaviours, and is crucial for understanding human internal and external states. In recent years, a large number of automatic personality computing approaches have been developed to predict either the apparent personality or self-reported personality of the subject based on non-verbal audio-visual behaviours. However, the majority of them suffer from complex and dataset-specific pre-processing steps and model training tricks. In the absence of a standardized benchmark with consistent experimental settings, it is not only impossible to fairly compare the real performances of these personality computing models but also makes them difficult to be reproduced. In this paper, we present the first reproducible audio-visual benchmarking framework to provide a fair and consistent evaluation of eight existing personality computing models (e.g., audio, visual and audio-visual) and seven standard deep learning models on both self-reported and apparent personality recognition tasks. Building upon a set of benchmarked models, we also investigate the impact of two previously-used long-term modelling strategies for summarising short-term/frame-level predictions on personality computing results. The results conclude: (i) apparent personality traits, inferred from facial behaviours by most benchmarked deep learning models, show more reliability than self-reported ones; (ii) visual models frequently achieved superior performances than audio models on personality recognition; (iii) non-verbal behaviours contribute differently in predicting different personality traits; and (iv) our reproduced personality computing models generally achieved worse performances than their original reported results. Our benchmark is publicly available at \url{https://github.com/liaorongfan/DeepPersonality}.
PDF Abstract Colab
Colab


 UDIVA
UDIVA
