APPLeNet: Visual Attention Parameterized Prompt Learning for Few-Shot Remote Sensing Image Generalization using CLIP
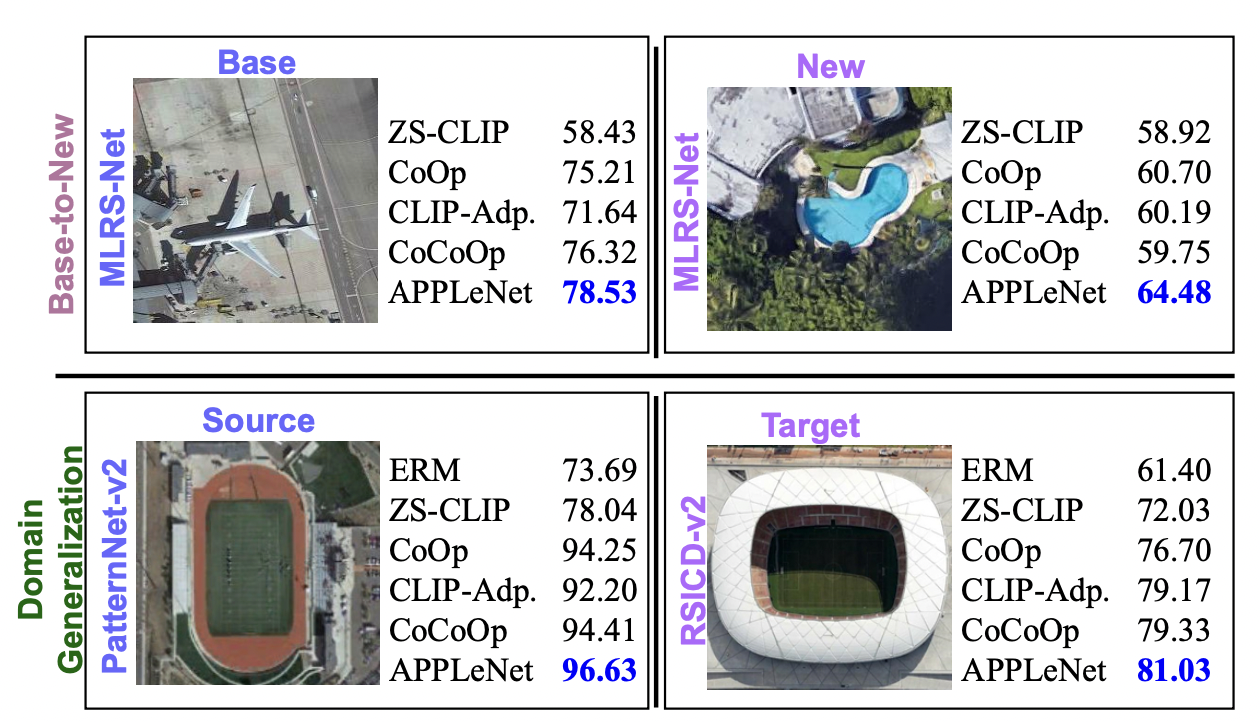
In recent years, the success of large-scale vision-language models (VLMs) such as CLIP has led to their increased usage in various computer vision tasks. These models enable zero-shot inference through carefully crafted instructional text prompts without task-specific supervision. However, the potential of VLMs for generalization tasks in remote sensing (RS) has not been fully realized. To address this research gap, we propose a novel image-conditioned prompt learning strategy called the Visual Attention Parameterized Prompts Learning Network (APPLeNet). APPLeNet emphasizes the importance of multi-scale feature learning in RS scene classification and disentangles visual style and content primitives for domain generalization tasks. To achieve this, APPLeNet combines visual content features obtained from different layers of the vision encoder and style properties obtained from feature statistics of domain-specific batches. An attention-driven injection module is further introduced to generate visual tokens from this information. We also introduce an anti-correlation regularizer to ensure discrimination among the token embeddings, as this visual information is combined with the textual tokens. To validate APPLeNet, we curated four available RS benchmarks and introduced experimental protocols and datasets for three domain generalization tasks. Our results consistently outperform the relevant literature and code is available at https://github.com/mainaksingha01/APPLeNet
PDF Abstract

 RESISC45
RESISC45
 RSICD
RSICD
