BinaryViT: Pushing Binary Vision Transformers Towards Convolutional Models
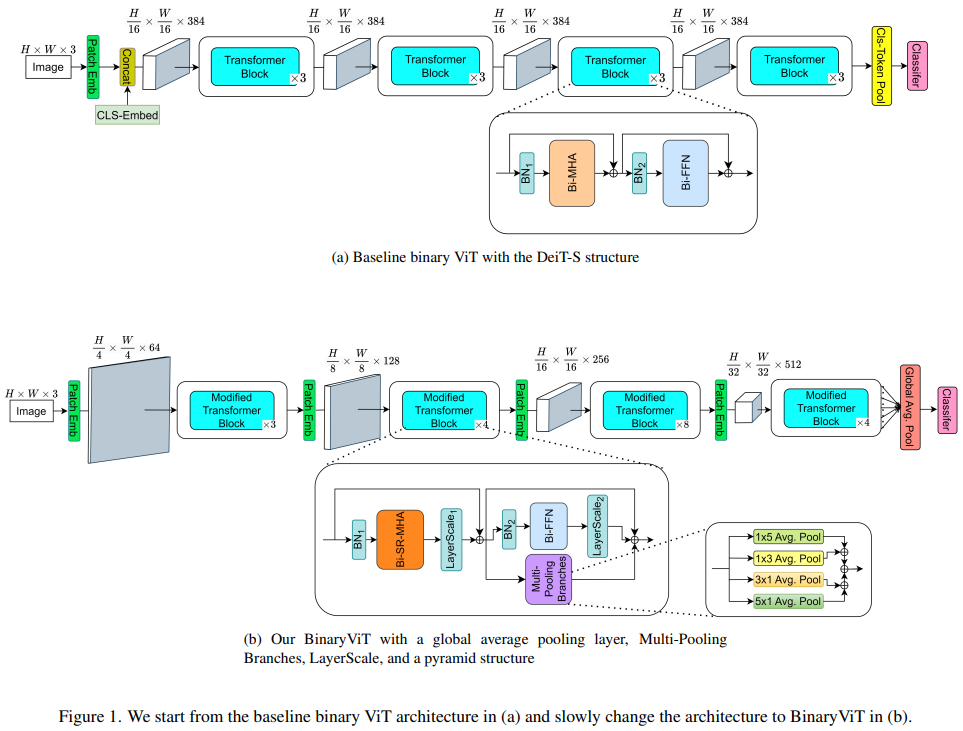
With the increasing popularity and the increasing size of vision transformers (ViTs), there has been an increasing interest in making them more efficient and less computationally costly for deployment on edge devices with limited computing resources. Binarization can be used to help reduce the size of ViT models and their computational cost significantly, using popcount operations when the weights and the activations are in binary. However, ViTs suffer a larger performance drop when directly applying convolutional neural network (CNN) binarization methods or existing binarization methods to binarize ViTs compared to CNNs on datasets with a large number of classes such as ImageNet-1k. With extensive analysis, we find that binary vanilla ViTs such as DeiT miss out on a lot of key architectural properties that CNNs have that allow binary CNNs to have much higher representational capability than binary vanilla ViT. Therefore, we propose BinaryViT, in which inspired by the CNN architecture, we include operations from the CNN architecture into a pure ViT architecture to enrich the representational capability of a binary ViT without introducing convolutions. These include an average pooling layer instead of a token pooling layer, a block that contains multiple average pooling branches, an affine transformation right before the addition of each main residual connection, and a pyramid structure. Experimental results on the ImageNet-1k dataset show the effectiveness of these operations that allow a binary pure ViT model to be competitive with previous state-of-the-art (SOTA) binary CNN models.
PDF Abstract

 ImageNet
ImageNet
