Coarse-Fine Networks for Temporal Activity Detection in Videos
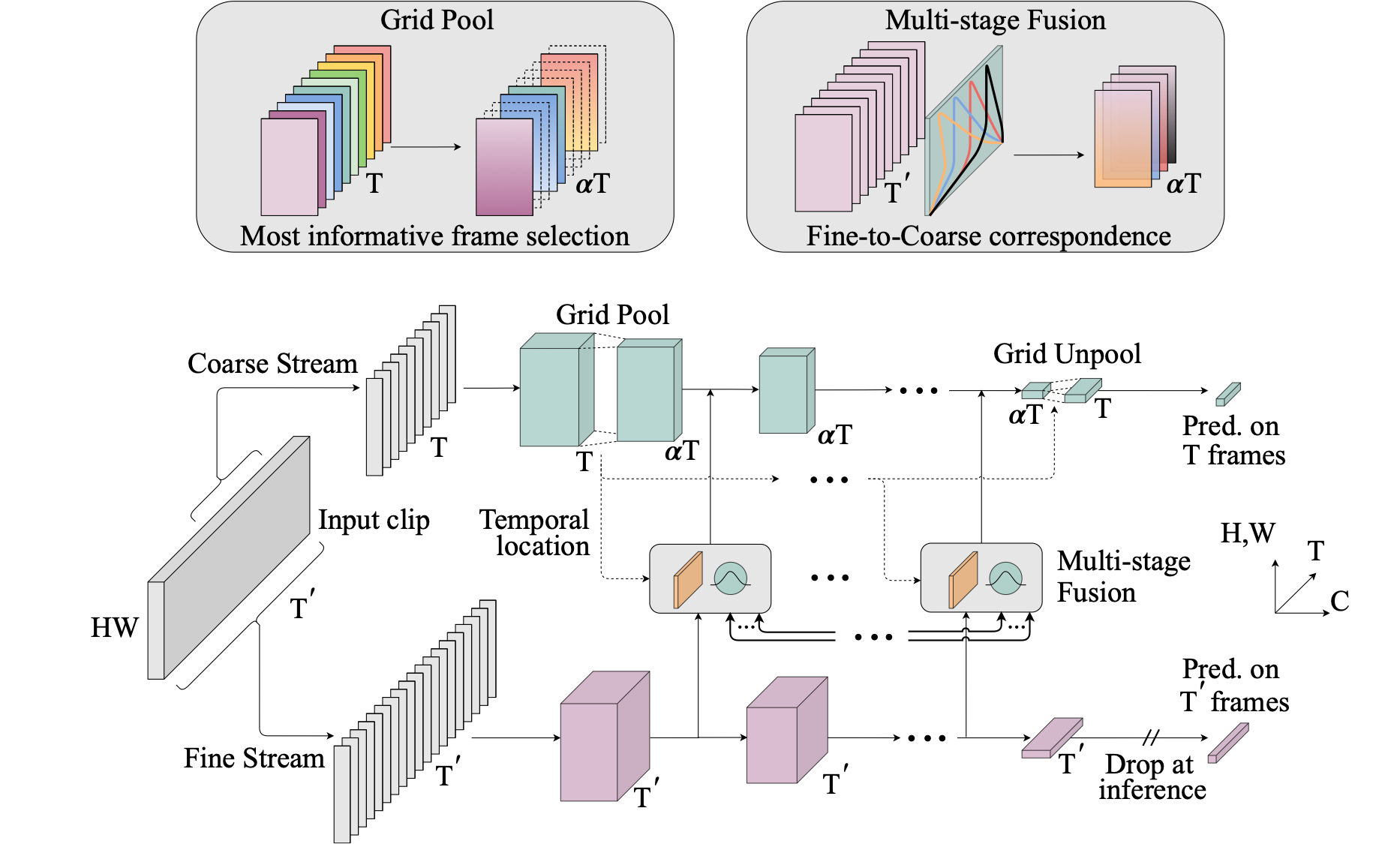
In this paper, we introduce Coarse-Fine Networks, a two-stream architecture which benefits from different abstractions of temporal resolution to learn better video representations for long-term motion. Traditional Video models process inputs at one (or few) fixed temporal resolution without any dynamic frame selection. However, we argue that, processing multiple temporal resolutions of the input and doing so dynamically by learning to estimate the importance of each frame can largely improve video representations, specially in the domain of temporal activity localization. To this end, we propose (1) Grid Pool, a learned temporal downsampling layer to extract coarse features, and, (2) Multi-stage Fusion, a spatio-temporal attention mechanism to fuse a fine-grained context with the coarse features. We show that our method outperforms the state-of-the-arts for action detection in public datasets including Charades with a significantly reduced compute and memory footprint. The code is available at https://github.com/kkahatapitiya/Coarse-Fine-Networks
PDF Abstract CVPR 2021 PDF CVPR 2021 Abstract


 Kinetics
Kinetics
 Kinetics 400
Kinetics 400
 Charades
Charades
 MultiTHUMOS
MultiTHUMOS

