Coarse-to-Fine Amodal Segmentation with Shape Prior
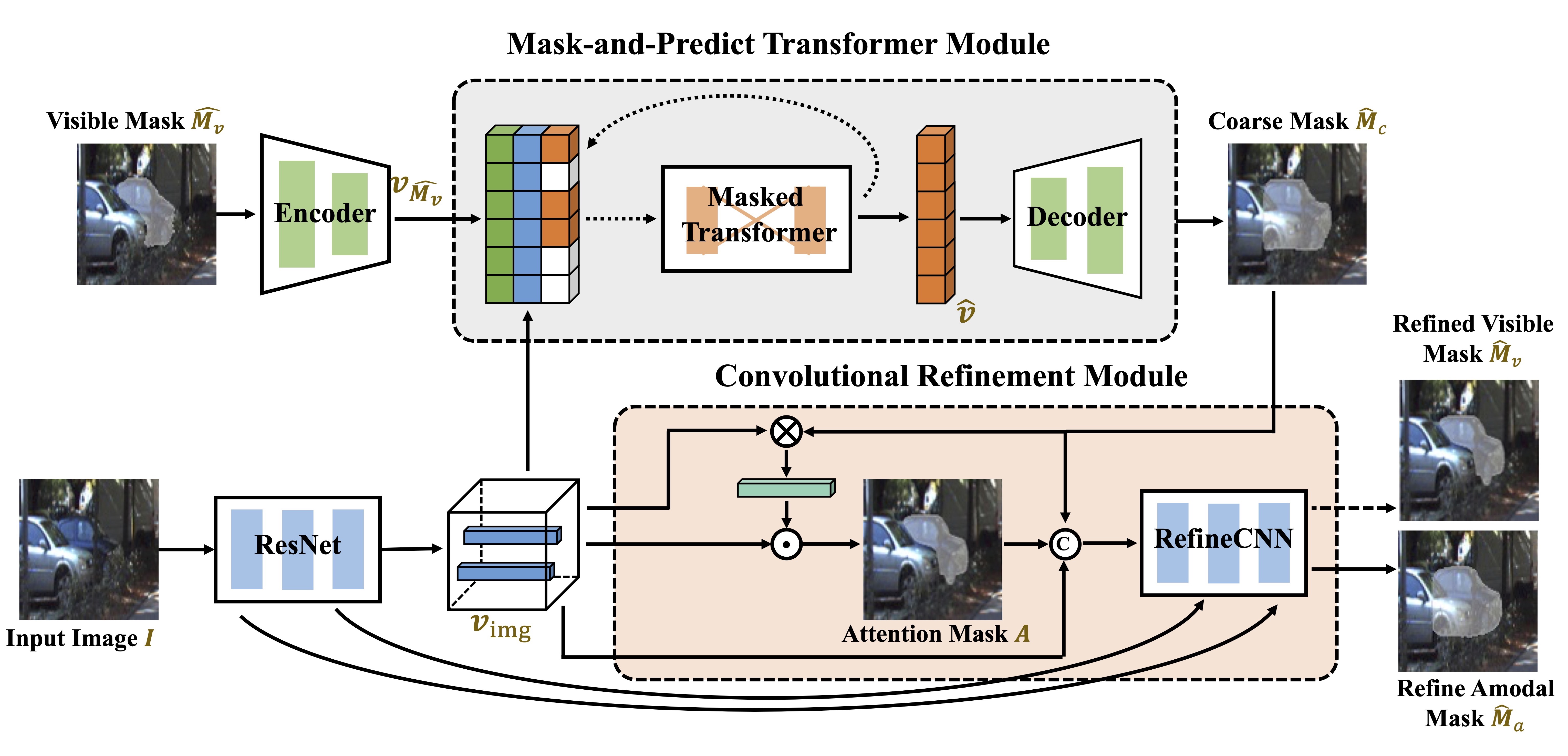
Amodal object segmentation is a challenging task that involves segmenting both visible and occluded parts of an object. In this paper, we propose a novel approach, called Coarse-to-Fine Segmentation (C2F-Seg), that addresses this problem by progressively modeling the amodal segmentation. C2F-Seg initially reduces the learning space from the pixel-level image space to the vector-quantized latent space. This enables us to better handle long-range dependencies and learn a coarse-grained amodal segment from visual features and visible segments. However, this latent space lacks detailed information about the object, which makes it difficult to provide a precise segmentation directly. To address this issue, we propose a convolution refine module to inject fine-grained information and provide a more precise amodal object segmentation based on visual features and coarse-predicted segmentation. To help the studies of amodal object segmentation, we create a synthetic amodal dataset, named as MOViD-Amodal (MOViD-A), which can be used for both image and video amodal object segmentation. We extensively evaluate our model on two benchmark datasets: KINS and COCO-A. Our empirical results demonstrate the superiority of C2F-Seg. Moreover, we exhibit the potential of our approach for video amodal object segmentation tasks on FISHBOWL and our proposed MOViD-A. Project page at: http://jianxgao.github.io/C2F-Seg.
PDF Abstract ICCV 2023 PDF ICCV 2023 Abstract


 MOViD-Amodal
MOViD-Amodal
