Contrastive Learning of Global-Local Video Representations
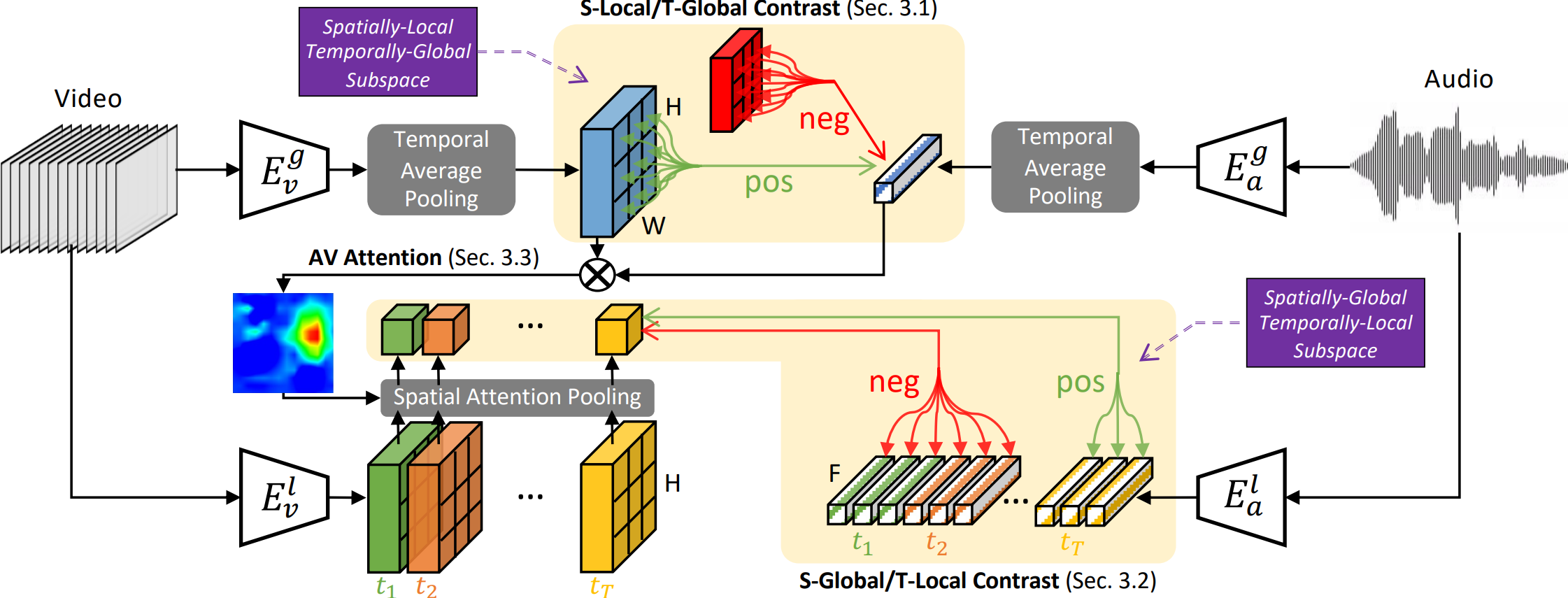
Contrastive learning has delivered impressive results for various tasks in the self-supervised regime. However, existing approaches optimize for learning representations specific to downstream scenarios, i.e., \textit{global} representations suitable for tasks such as classification or \textit{local} representations for tasks such as detection and localization. While they produce satisfactory results in the intended downstream scenarios, they often fail to generalize to tasks that they were not originally designed for. In this work, we propose to learn video representations that generalize to both the tasks which require global semantic information (e.g., classification) and the tasks that require local fine-grained spatio-temporal information (e.g., localization). We achieve this by optimizing two contrastive objectives that together encourage our model to learn global-local visual information given audio signals. We show that the two objectives mutually improve the generalizability of the learned global-local representations, significantly outperforming their disjointly learned counterparts. We demonstrate our approach on various tasks including action/sound classification, lip reading, deepfake detection, event and sound localization (https://github.com/yunyikristy/global\_local).
PDF Abstract







 UCF101
UCF101
 Kinetics
Kinetics
 HMDB51
HMDB51
 Kinetics 400
Kinetics 400
 AudioSet
AudioSet
 ESC-50
ESC-50
 LRW
LRW
 DFDC
DFDC
 LRS2
LRS2
 AVSpeech
AVSpeech
