Cross-Lingual Cross-Modal Retrieval with Noise-Robust Learning
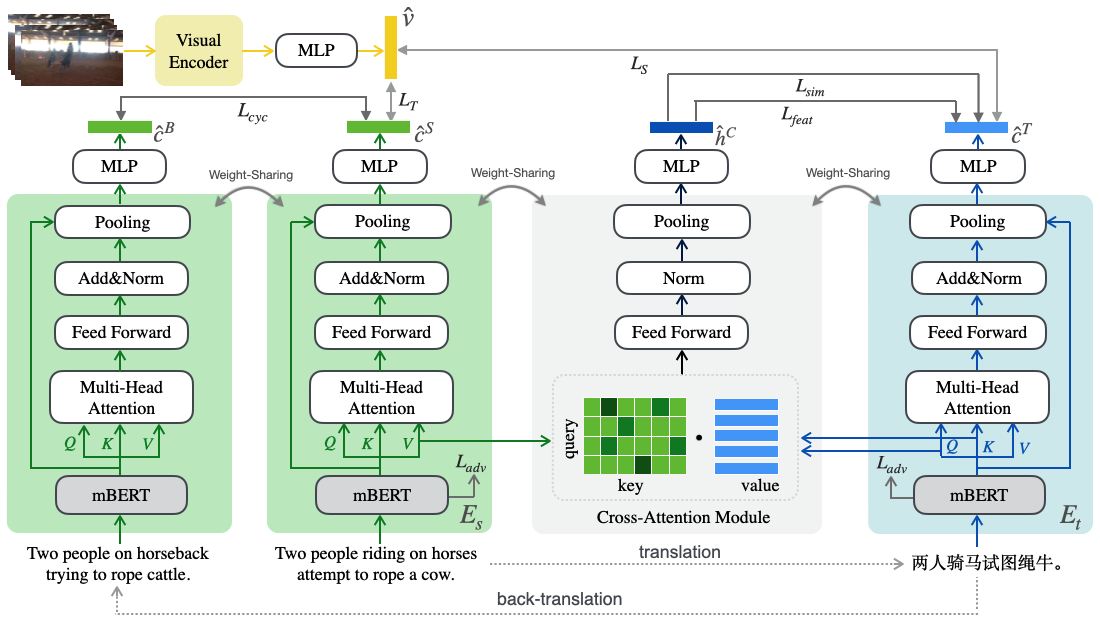
Despite the recent developments in the field of cross-modal retrieval, there has been less research focusing on low-resource languages due to the lack of manually annotated datasets. In this paper, we propose a noise-robust cross-lingual cross-modal retrieval method for low-resource languages. To this end, we use Machine Translation (MT) to construct pseudo-parallel sentence pairs for low-resource languages. However, as MT is not perfect, it tends to introduce noise during translation, rendering textual embeddings corrupted and thereby compromising the retrieval performance. To alleviate this, we introduce a multi-view self-distillation method to learn noise-robust target-language representations, which employs a cross-attention module to generate soft pseudo-targets to provide direct supervision from the similarity-based view and feature-based view. Besides, inspired by the back-translation in unsupervised MT, we minimize the semantic discrepancies between origin sentences and back-translated sentences to further improve the noise robustness of the textual encoder. Extensive experiments are conducted on three video-text and image-text cross-modal retrieval benchmarks across different languages, and the results demonstrate that our method significantly improves the overall performance without using extra human-labeled data. In addition, equipped with a pre-trained visual encoder from a recent vision-and-language pre-training framework, i.e., CLIP, our model achieves a significant performance gain, showing that our method is compatible with popular pre-training models. Code and data are available at https://github.com/HuiGuanLab/nrccr.
PDF Abstract


 Flickr30k
Flickr30k
 MSR-VTT
MSR-VTT
 Conceptual Captions
Conceptual Captions
 HowTo100M
HowTo100M
