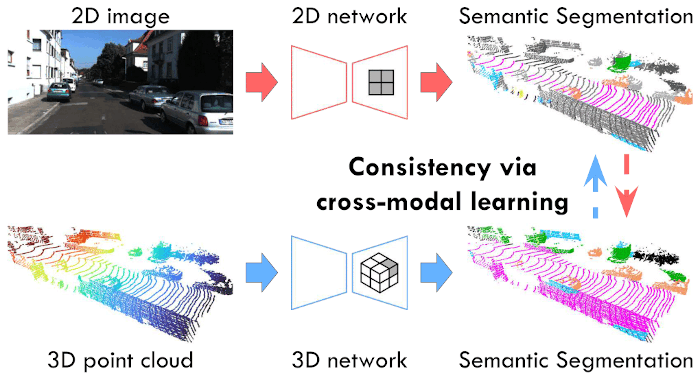
Cross-modal Learning for Domain Adaptation in 3D Semantic Segmentation
Domain adaptation is an important task to enable learning when labels are scarce. While most works focus only on the image modality, there are many important multi-modal datasets. In order to leverage multi-modality for domain adaptation, we propose cross-modal learning, where we enforce consistency between the predictions of two modalities via mutual mimicking. We constrain our network to make correct predictions on labeled data and consistent predictions across modalities on unlabeled target-domain data. Experiments in unsupervised and semi-supervised domain adaptation settings prove the effectiveness of this novel domain adaptation strategy. Specifically, we evaluate on the task of 3D semantic segmentation from either the 2D image, the 3D point cloud or from both. We leverage recent driving datasets to produce a wide variety of domain adaptation scenarios including changes in scene layout, lighting, sensor setup and weather, as well as the synthetic-to-real setup. Our method significantly improves over previous uni-modal adaptation baselines on all adaption scenarios. Our code is publicly available at https://github.com/valeoai/xmuda_journal
PDF Abstract






 CIFAR-100
CIFAR-100
 KITTI
KITTI
 nuScenes
nuScenes
 SemanticKITTI
SemanticKITTI
 Waymo Open Dataset
Waymo Open Dataset
 Virtual KITTI
Virtual KITTI

