Cross3DVG: Cross-Dataset 3D Visual Grounding on Different RGB-D Scans
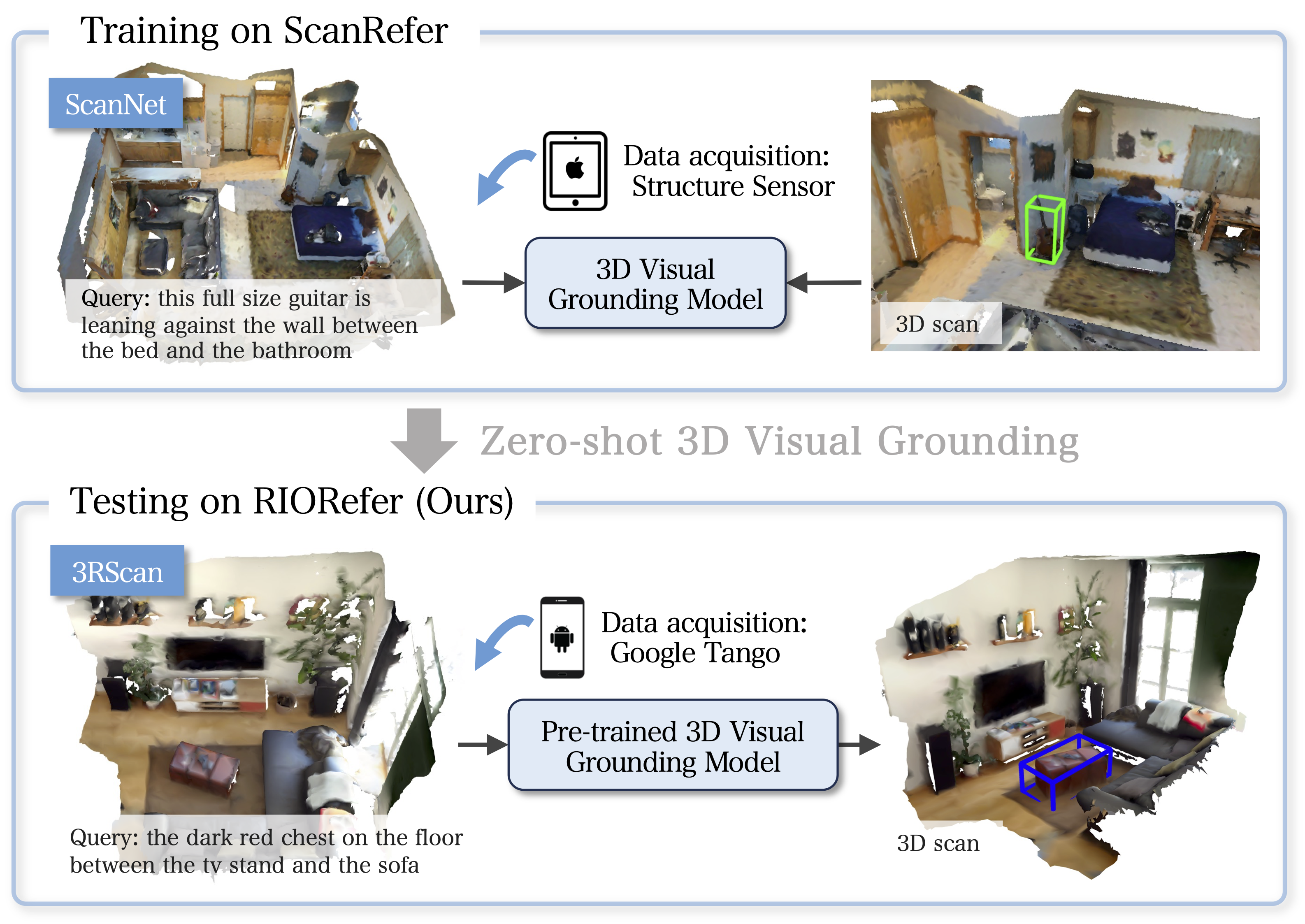
We present a novel task for cross-dataset visual grounding in 3D scenes (Cross3DVG), which overcomes limitations of existing 3D visual grounding models, specifically their restricted 3D resources and consequent tendencies of overfitting a specific 3D dataset. We created RIORefer, a large-scale 3D visual grounding dataset, to facilitate Cross3DVG. It includes more than 63k diverse descriptions of 3D objects within 1,380 indoor RGB-D scans from 3RScan, with human annotations. After training the Cross3DVG model using the source 3D visual grounding dataset, we evaluate it without target labels using the target dataset with, e.g., different sensors, 3D reconstruction methods, and language annotators. Comprehensive experiments are conducted using established visual grounding models and with CLIP-based multi-view 2D and 3D integration designed to bridge gaps among 3D datasets. For Cross3DVG tasks, (i) cross-dataset 3D visual grounding exhibits significantly worse performance than learning and evaluation with a single dataset because of the 3D data and language variants across datasets. Moreover, (ii) better object detector and localization modules and fusing 3D data and multi-view CLIP-based image features can alleviate this lower performance. Our Cross3DVG task can provide a benchmark for developing robust 3D visual grounding models to handle diverse 3D scenes while leveraging deep language understanding.
PDF Abstract


 ScanNet
ScanNet
 SUN RGB-D
SUN RGB-D
