DeepSolo: Let Transformer Decoder with Explicit Points Solo for Text Spotting
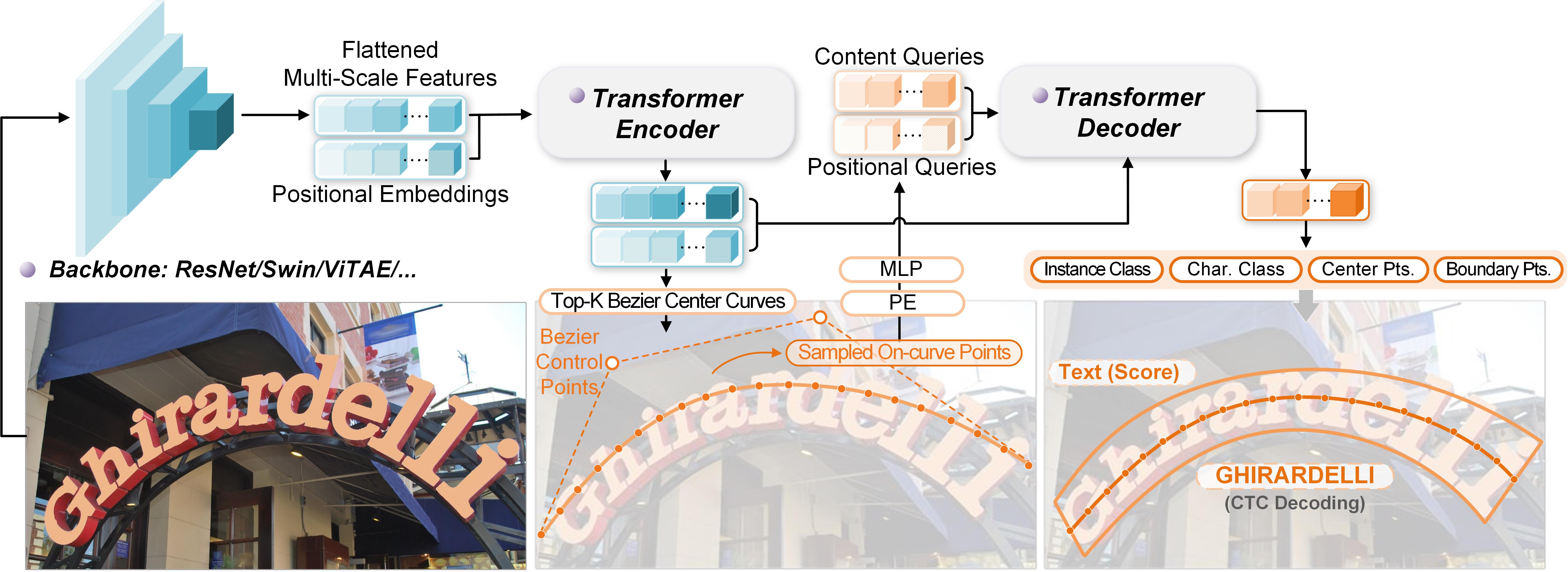
End-to-end text spotting aims to integrate scene text detection and recognition into a unified framework. Dealing with the relationship between the two sub-tasks plays a pivotal role in designing effective spotters. Although Transformer-based methods eliminate the heuristic post-processing, they still suffer from the synergy issue between the sub-tasks and low training efficiency. In this paper, we present DeepSolo, a simple DETR-like baseline that lets a single Decoder with Explicit Points Solo for text detection and recognition simultaneously. Technically, for each text instance, we represent the character sequence as ordered points and model them with learnable explicit point queries. After passing a single decoder, the point queries have encoded requisite text semantics and locations, thus can be further decoded to the center line, boundary, script, and confidence of text via very simple prediction heads in parallel. Besides, we also introduce a text-matching criterion to deliver more accurate supervisory signals, thus enabling more efficient training. Quantitative experiments on public benchmarks demonstrate that DeepSolo outperforms previous state-of-the-art methods and achieves better training efficiency. In addition, DeepSolo is also compatible with line annotations, which require much less annotation cost than polygons. The code is available at https://github.com/ViTAE-Transformer/DeepSolo.
PDF Abstract CVPR 2023 PDF CVPR 2023 Abstract

Datasets
 ICDAR 2013
ICDAR 2013
 Total-Text
Total-Text
Results from the Paper
 Ranked #1 on
Text Spotting
on Total-Text
(using extra training data)
Ranked #1 on
Text Spotting
on Total-Text
(using extra training data)
