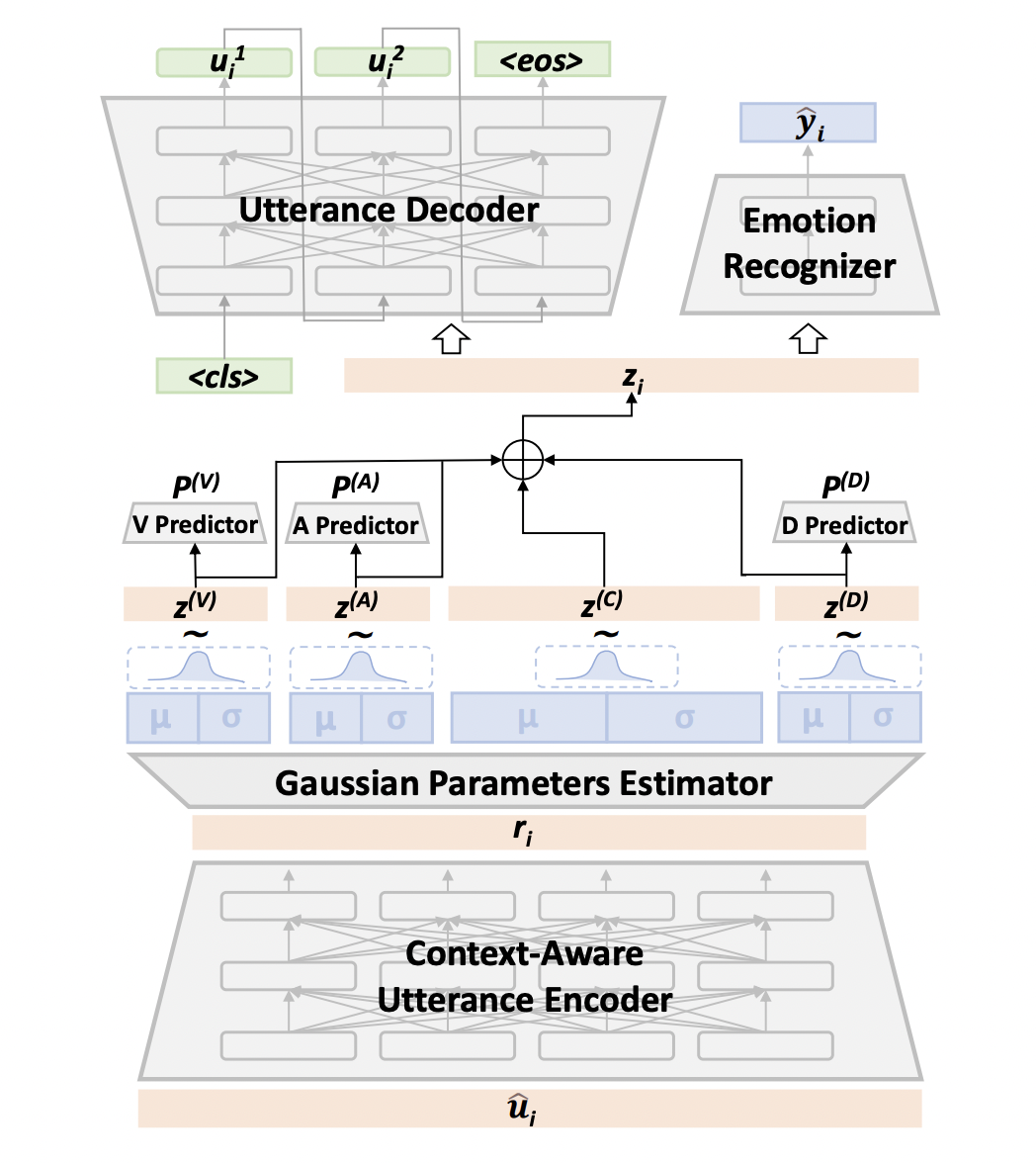
Disentangled Variational Autoencoder for Emotion Recognition in Conversations
In Emotion Recognition in Conversations (ERC), the emotions of target utterances are closely dependent on their context. Therefore, existing works train the model to generate the response of the target utterance, which aims to recognise emotions leveraging contextual information. However, adjacent response generation ignores long-range dependencies and provides limited affective information in many cases. In addition, most ERC models learn a unified distributed representation for each utterance, which lacks interpretability and robustness. To address these issues, we propose a VAD-disentangled Variational AutoEncoder (VAD-VAE), which first introduces a target utterance reconstruction task based on Variational Autoencoder, then disentangles three affect representations Valence-Arousal-Dominance (VAD) from the latent space. We also enhance the disentangled representations by introducing VAD supervision signals from a sentiment lexicon and minimising the mutual information between VAD distributions. Experiments show that VAD-VAE outperforms the state-of-the-art model on two datasets. Further analysis proves the effectiveness of each proposed module and the quality of disentangled VAD representations. The code is available at https://github.com/SteveKGYang/VAD-VAE.
PDF Abstract

 IEMOCAP
IEMOCAP
 DailyDialog
DailyDialog
 MELD
MELD
