Domain generalization of 3D semantic segmentation in autonomous driving
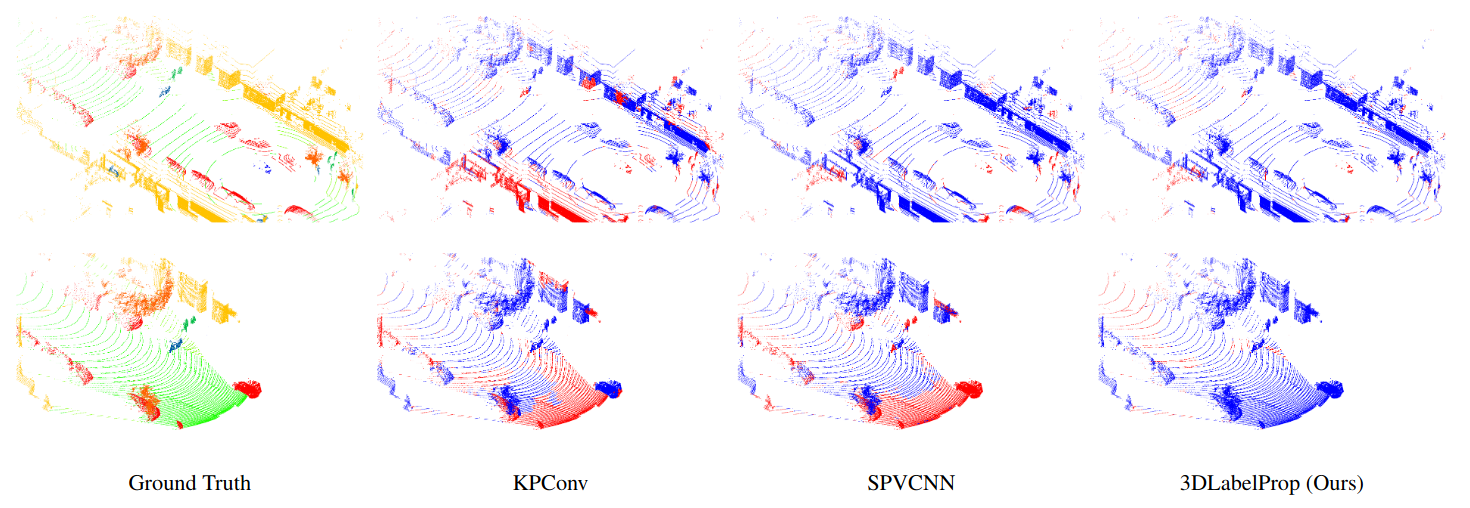
Using deep learning, 3D autonomous driving semantic segmentation has become a well-studied subject, with methods that can reach very high performance. Nonetheless, because of the limited size of the training datasets, these models cannot see every type of object and scene found in real-world applications. The ability to be reliable in these various unknown environments is called \textup{domain generalization}. Despite its importance, domain generalization is relatively unexplored in the case of 3D autonomous driving semantic segmentation. To fill this gap, this paper presents the first benchmark for this application by testing state-of-the-art methods and discussing the difficulty of tackling Laser Imaging Detection and Ranging (LiDAR) domain shifts. We also propose the first method designed to address this domain generalization, which we call 3DLabelProp. This method relies on leveraging the geometry and sequentiality of the LiDAR data to enhance its generalization performances by working on partially accumulated point clouds. It reaches a mean Intersection over Union (mIoU) of 50.4% on SemanticPOSS and of 55.2% on PandaSet solid-state LiDAR while being trained only on SemanticKITTI, making it the state-of-the-art method for generalization (+5% and +33% better, respectively, than the second best method). The code for this method is available on GitHub: https://github.com/JulesSanchez/3DLabelProp.
PDF Abstract ICCV 2023 PDF ICCV 2023 Abstract




 nuScenes
nuScenes
 SemanticKITTI
SemanticKITTI
 SemanticPOSS
SemanticPOSS
