EfficientTrain++: Generalized Curriculum Learning for Efficient Visual Backbone Training
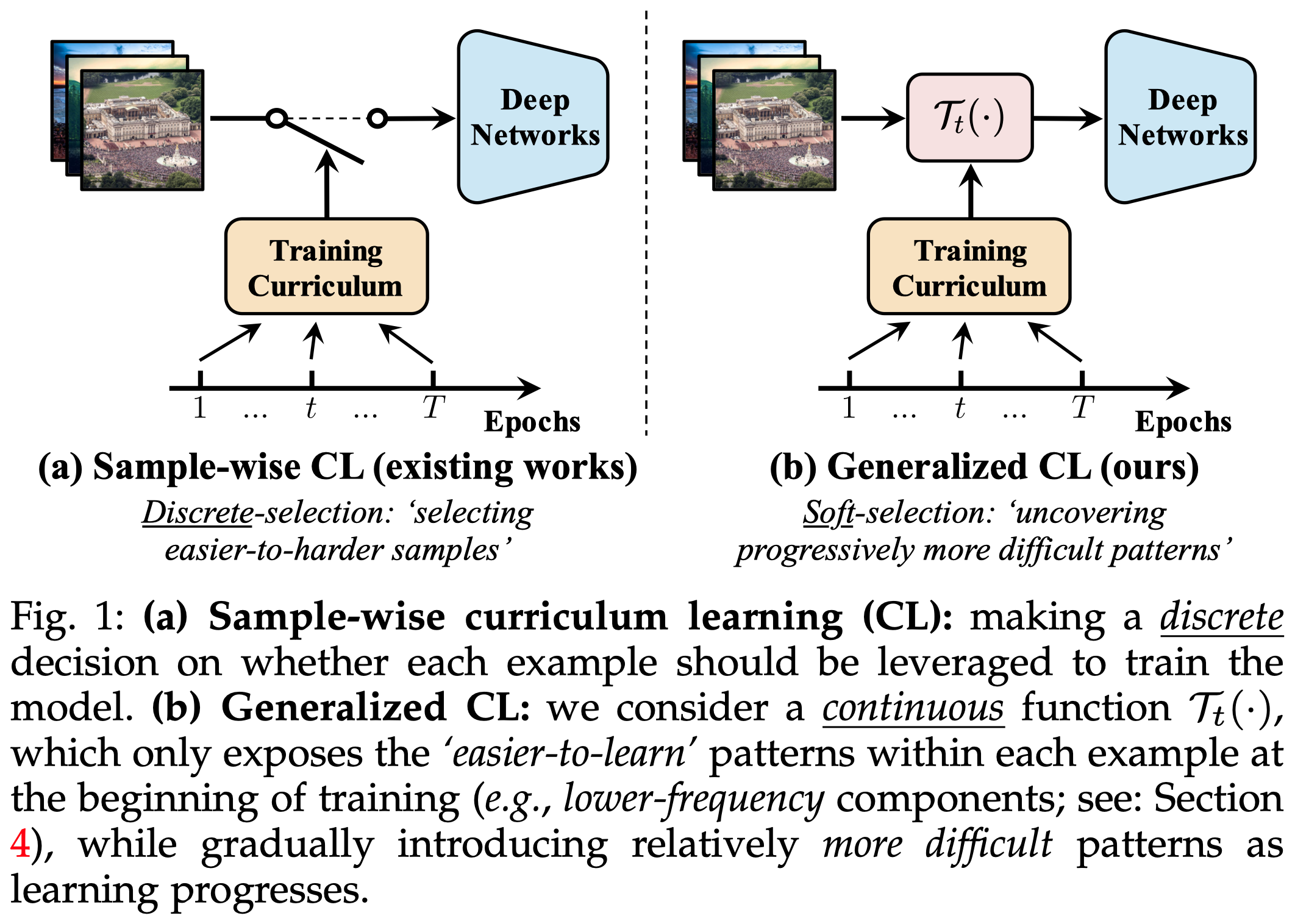
The superior performance of modern visual backbones usually comes with a costly training procedure. We contribute to this issue by generalizing the idea of curriculum learning beyond its original formulation, i.e., training models using easier-to-harder data. Specifically, we reformulate the training curriculum as a soft-selection function, which uncovers progressively more difficult patterns within each example during training, instead of performing easier-to-harder sample selection. Our work is inspired by an intriguing observation on the learning dynamics of visual backbones: during the earlier stages of training, the model predominantly learns to recognize some 'easier-to-learn' discriminative patterns in the data. These patterns, when observed through frequency and spatial domains, incorporate lower-frequency components, and the natural image contents without distortion or data augmentation. Motivated by these findings, we propose a curriculum where the model always leverages all the training data at every learning stage, yet the exposure to the 'easier-to-learn' patterns of each example is initiated first, with harder patterns gradually introduced as training progresses. To implement this idea in a computationally efficient way, we introduce a cropping operation in the Fourier spectrum of the inputs, enabling the model to learn from only the lower-frequency components. Then we show that exposing the contents of natural images can be readily achieved by modulating the intensity of data augmentation. Finally, we integrate these aspects and design curriculum schedules with tailored search algorithms. The resulting method, EfficientTrain++, is simple, general, yet surprisingly effective. It reduces the training time of a wide variety of popular models by 1.5-3.0x on ImageNet-1K/22K without sacrificing accuracy. It also demonstrates efficacy in self-supervised learning (e.g., MAE).
PDF Abstract


 ImageNet
ImageNet
 MS COCO
MS COCO
 Oxford 102 Flower
Oxford 102 Flower
 Food-101
Food-101
