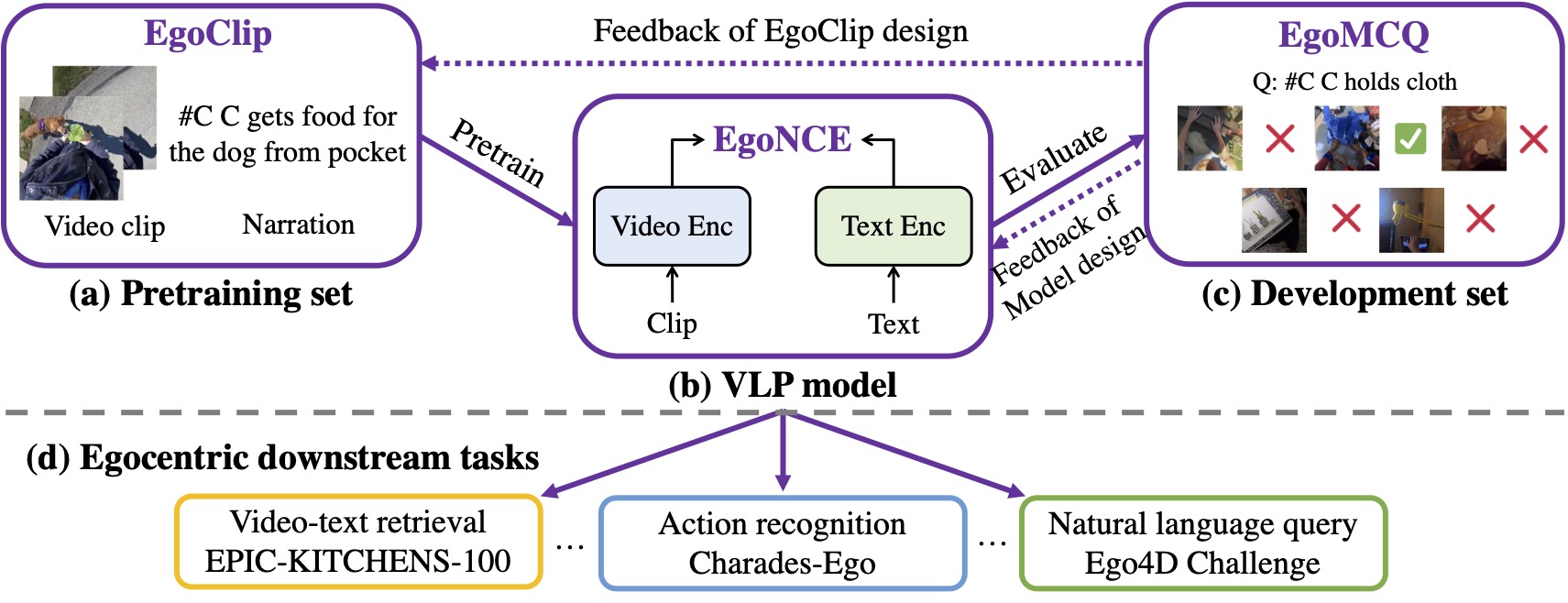
Egocentric Video-Language Pretraining
Video-Language Pretraining (VLP), which aims to learn transferable representation to advance a wide range of video-text downstream tasks, has recently received increasing attention. Best performing works rely on large-scale, 3rd-person video-text datasets, such as HowTo100M. In this work, we exploit the recently released Ego4D dataset to pioneer Egocentric VLP along three directions. (i) We create EgoClip, a 1st-person video-text pretraining dataset comprising 3.8M clip-text pairs well-chosen from Ego4D, covering a large variety of human daily activities. (ii) We propose a novel pretraining objective, dubbed EgoNCE, which adapts video-text contrastive learning to the egocentric domain by mining egocentric-aware positive and negative samples. (iii) We introduce EgoMCQ, a development benchmark that is close to EgoClip and hence can support effective validation and fast exploration of our design decisions in EgoClip and EgoNCE. Furthermore, we demonstrate strong performance on five egocentric downstream tasks across three datasets: video-text retrieval on EPIC-KITCHENS-100; action recognition on Charades-Ego; natural language query, moment query, and object state change classification on Ego4D challenge benchmarks. The dataset and code are available at https://github.com/showlab/EgoVLP.
PDF Abstract





 HowTo100M
HowTo100M
 WebVid
WebVid
 EPIC-KITCHENS-100
EPIC-KITCHENS-100
 Ego4D
Ego4D
 EgoTaskQA
EgoTaskQA

