EventCLIP: Adapting CLIP for Event-based Object Recognition
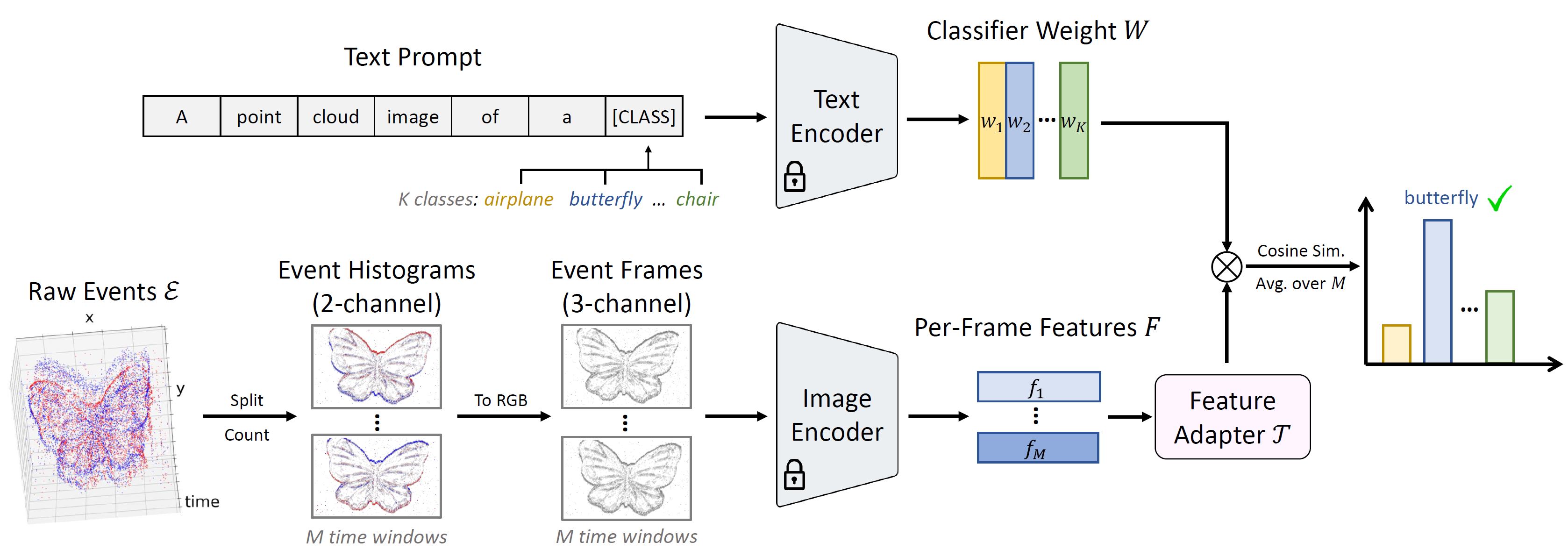
Recent advances in zero-shot and few-shot classification heavily rely on the success of pre-trained vision-language models (VLMs) such as CLIP. Due to a shortage of large-scale datasets, training such models for event camera data remains infeasible. Thus, adapting existing VLMs across modalities to event vision is an important research challenge. In this work, we introduce EventCLIP, a novel approach that utilizes CLIP for zero-shot and few-shot event-based object recognition. We first generalize CLIP's image encoder to event data by converting raw events to 2D grid-based representations. To further enhance performance, we propose a feature adapter to aggregate temporal information over event frames and refine text embeddings to better align with the visual inputs. We evaluate EventCLIP on N-Caltech, N-Cars, and N-ImageNet datasets, achieving state-of-the-art few-shot performance. When fine-tuned on the entire dataset, our method outperforms all existing event classifiers. Moreover, we explore practical applications of EventCLIP including robust event classification and label-free event recognition, where our approach surpasses previous baselines designed specifically for these tasks.
PDF Abstract


 N-Caltech 101
N-Caltech 101
 N-ImageNet
N-ImageNet
