Explicit Visual Prompts for Visual Object Tracking
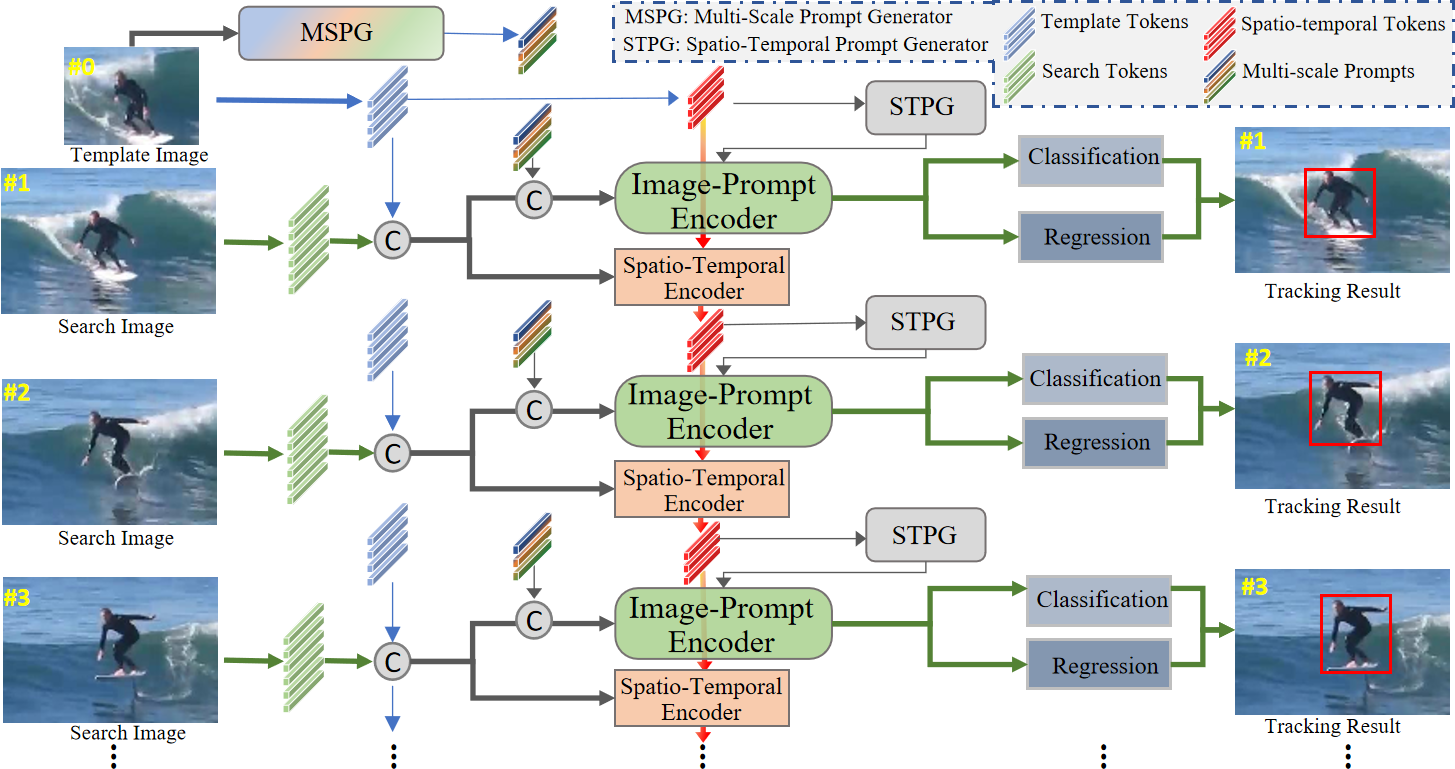
How to effectively exploit spatio-temporal information is crucial to capture target appearance changes in visual tracking. However, most deep learning-based trackers mainly focus on designing a complicated appearance model or template updating strategy, while lacking the exploitation of context between consecutive frames and thus entailing the \textit{when-and-how-to-update} dilemma. To address these issues, we propose a novel explicit visual prompts framework for visual tracking, dubbed \textbf{EVPTrack}. Specifically, we utilize spatio-temporal tokens to propagate information between consecutive frames without focusing on updating templates. As a result, we cannot only alleviate the challenge of \textit{when-to-update}, but also avoid the hyper-parameters associated with updating strategies. Then, we utilize the spatio-temporal tokens to generate explicit visual prompts that facilitate inference in the current frame. The prompts are fed into a transformer encoder together with the image tokens without additional processing. Consequently, the efficiency of our model is improved by avoiding \textit{how-to-update}. In addition, we consider multi-scale information as explicit visual prompts, providing multiscale template features to enhance the EVPTrack's ability to handle target scale changes. Extensive experimental results on six benchmarks (i.e., LaSOT, LaSOT\rm $_{ext}$, GOT-10k, UAV123, TrackingNet, and TNL2K.) validate that our EVPTrack can achieve competitive performance at a real-time speed by effectively exploiting both spatio-temporal and multi-scale information. Code and models are available at https://github.com/GXNU-ZhongLab/EVPTrack.
PDF Abstract


 GOT-10k
GOT-10k
 TrackingNet
TrackingNet
