Exploring Sparse Visual Prompt for Domain Adaptive Dense Prediction
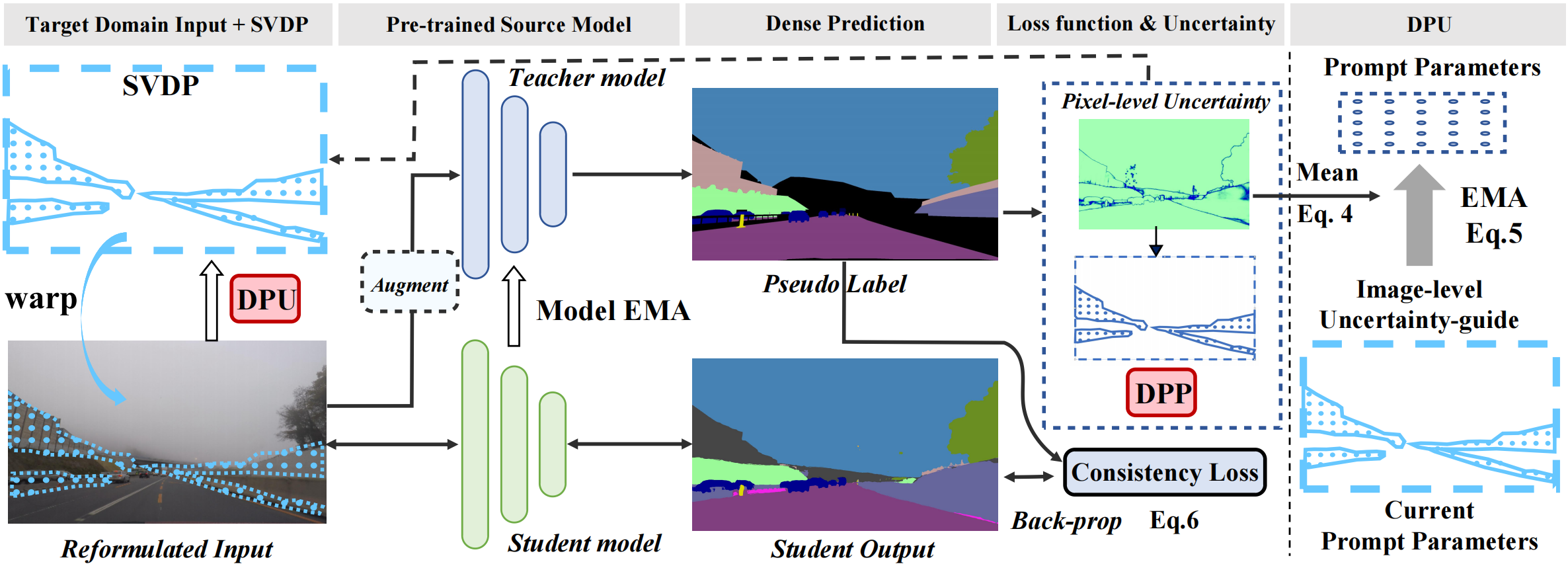
The visual prompts have provided an efficient manner in addressing visual cross-domain problems. In previous works, Visual Domain Prompt (VDP) first introduces domain prompts to tackle the classification Test-Time Adaptation (TTA) problem by warping image-level prompts on the input and fine-tuning prompts for each target domain. However, since the image-level prompts mask out continuous spatial details in the prompt-allocated region, it will suffer from inaccurate contextual information and limited domain knowledge extraction, particularly when dealing with dense prediction TTA problems. To overcome these challenges, we propose a novel Sparse Visual Domain Prompts (SVDP) approach, which holds minimal trainable parameters (e.g., 0.1\%) in the image-level prompt and reserves more spatial information of the input. To better apply SVDP in extracting domain-specific knowledge, we introduce the Domain Prompt Placement (DPP) method to adaptively allocates trainable parameters of SVDP on the pixels with large distribution shifts. Furthermore, recognizing that each target domain sample exhibits a unique domain shift, we design Domain Prompt Updating (DPU) strategy to optimize prompt parameters differently for each sample, facilitating efficient adaptation to the target domain. Extensive experiments were conducted on widely-used TTA and continual TTA benchmarks, and our proposed method achieves state-of-the-art performance in both semantic segmentation and depth estimation tasks.
PDF Abstract




 Cityscapes
Cityscapes
 KITTI
KITTI
 DrivingStereo
DrivingStereo
