FastMIM: Expediting Masked Image Modeling Pre-training for Vision
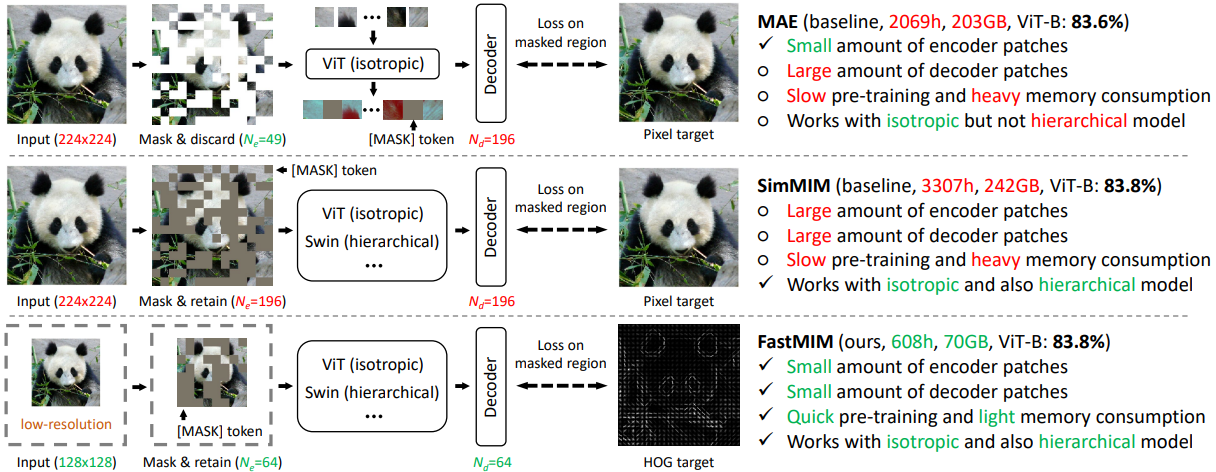
The combination of transformers and masked image modeling (MIM) pre-training framework has shown great potential in various vision tasks. However, the pre-training computational budget is too heavy and withholds the MIM from becoming a practical training paradigm. This paper presents FastMIM, a simple and generic framework for expediting masked image modeling with the following two steps: (i) pre-training vision backbones with low-resolution input images; and (ii) reconstructing Histograms of Oriented Gradients (HOG) feature instead of original RGB values of the input images. In addition, we propose FastMIM-P to progressively enlarge the input resolution during pre-training stage to further enhance the transfer results of models with high capacity. We point out that: (i) a wide range of input resolutions in pre-training phase can lead to similar performances in fine-tuning phase and downstream tasks such as detection and segmentation; (ii) the shallow layers of encoder are more important during pre-training and discarding last several layers can speed up the training stage with no harm to fine-tuning performance; (iii) the decoder should match the size of selected network; and (iv) HOG is more stable than RGB values when resolution transfers;. Equipped with FastMIM, all kinds of vision backbones can be pre-trained in an efficient way. For example, we can achieve 83.8%/84.1% top-1 accuracy on ImageNet-1K with ViT-B/Swin-B as backbones. Compared to previous relevant approaches, we can achieve comparable or better top-1 accuracy while accelerate the training procedure by $\sim$5$\times$. Code can be found in https://github.com/ggjy/FastMIM.pytorch.
PDF Abstract
 ImageNet
ImageNet
 MS COCO
MS COCO
 ADE20K
ADE20K
