Fine-Grained Predicates Learning for Scene Graph Generation
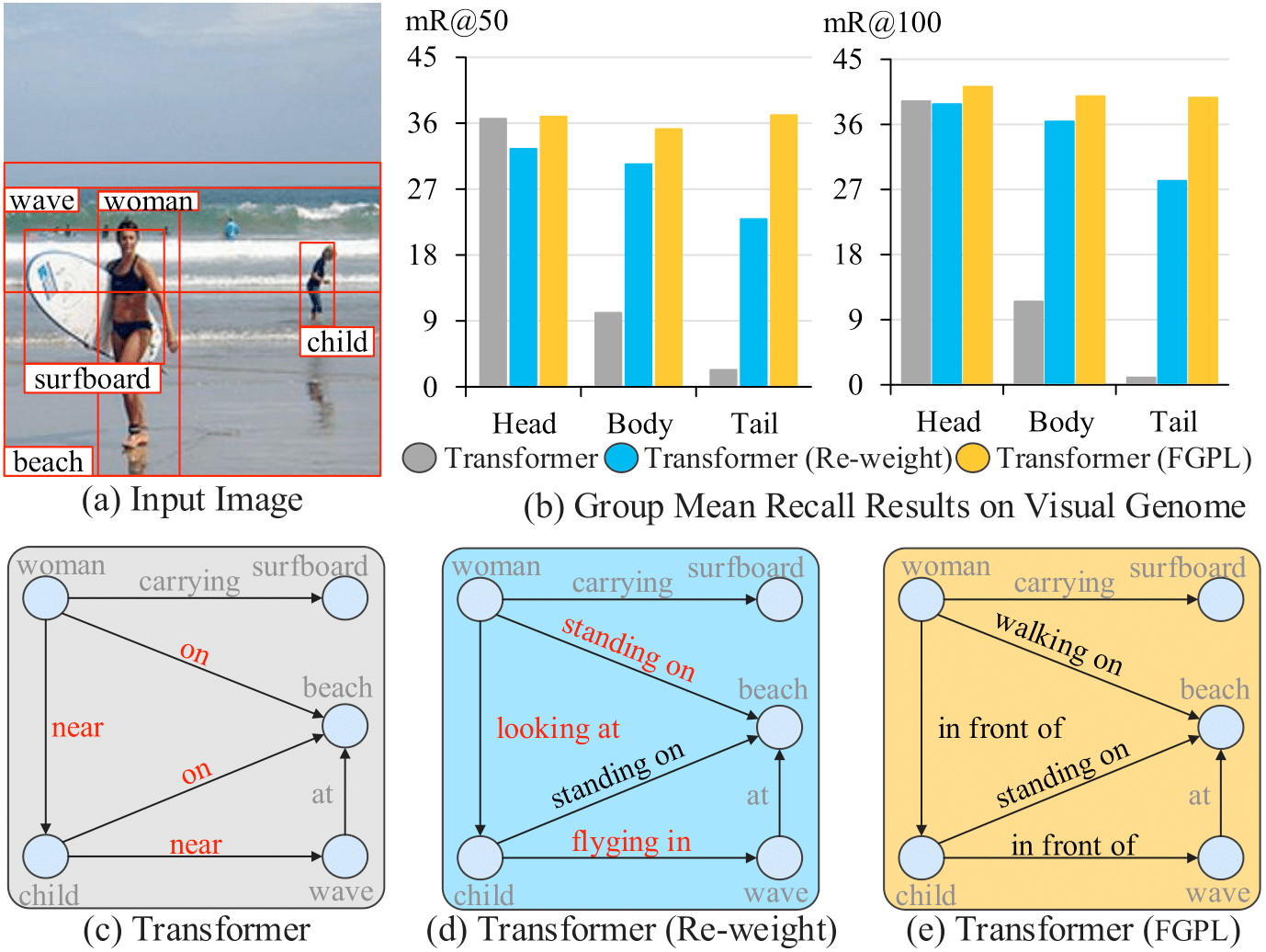
The performance of current Scene Graph Generation models is severely hampered by some hard-to-distinguish predicates, e.g., "woman-on/standing on/walking on-beach" or "woman-near/looking at/in front of-child". While general SGG models are prone to predict head predicates and existing re-balancing strategies prefer tail categories, none of them can appropriately handle these hard-to-distinguish predicates. To tackle this issue, inspired by fine-grained image classification, which focuses on differentiating among hard-to-distinguish object classes, we propose a method named Fine-Grained Predicates Learning (FGPL) which aims at differentiating among hard-to-distinguish predicates for Scene Graph Generation task. Specifically, we first introduce a Predicate Lattice that helps SGG models to figure out fine-grained predicate pairs. Then, utilizing the Predicate Lattice, we propose a Category Discriminating Loss and an Entity Discriminating Loss, which both contribute to distinguishing fine-grained predicates while maintaining learned discriminatory power over recognizable ones. The proposed model-agnostic strategy significantly boosts the performances of three benchmark models (Transformer, VCTree, and Motif) by 22.8\%, 24.1\% and 21.7\% of Mean Recall (mR@100) on the Predicate Classification sub-task, respectively. Our model also outperforms state-of-the-art methods by a large margin (i.e., 6.1\%, 4.6\%, and 3.2\% of Mean Recall (mR@100)) on the Visual Genome dataset.
PDF Abstract CVPR 2022 PDF CVPR 2022 Abstract



