FreeVC: Towards High-Quality Text-Free One-Shot Voice Conversion
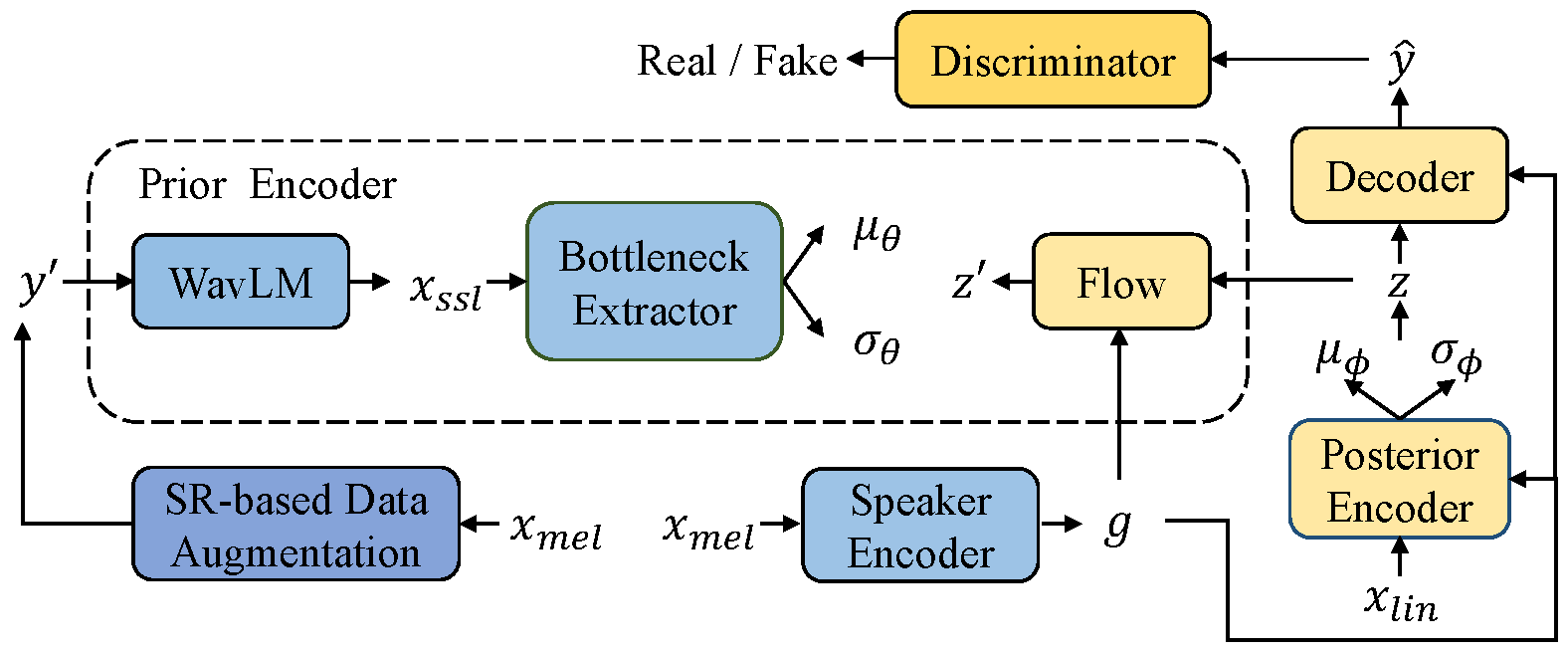
Voice conversion (VC) can be achieved by first extracting source content information and target speaker information, and then reconstructing waveform with these information. However, current approaches normally either extract dirty content information with speaker information leaked in, or demand a large amount of annotated data for training. Besides, the quality of reconstructed waveform can be degraded by the mismatch between conversion model and vocoder. In this paper, we adopt the end-to-end framework of VITS for high-quality waveform reconstruction, and propose strategies for clean content information extraction without text annotation. We disentangle content information by imposing an information bottleneck to WavLM features, and propose the spectrogram-resize based data augmentation to improve the purity of extracted content information. Experimental results show that the proposed method outperforms the latest VC models trained with annotated data and has greater robustness.
PDF Abstract Spaces
Spaces



