GEN-VLKT: Simplify Association and Enhance Interaction Understanding for HOI Detection
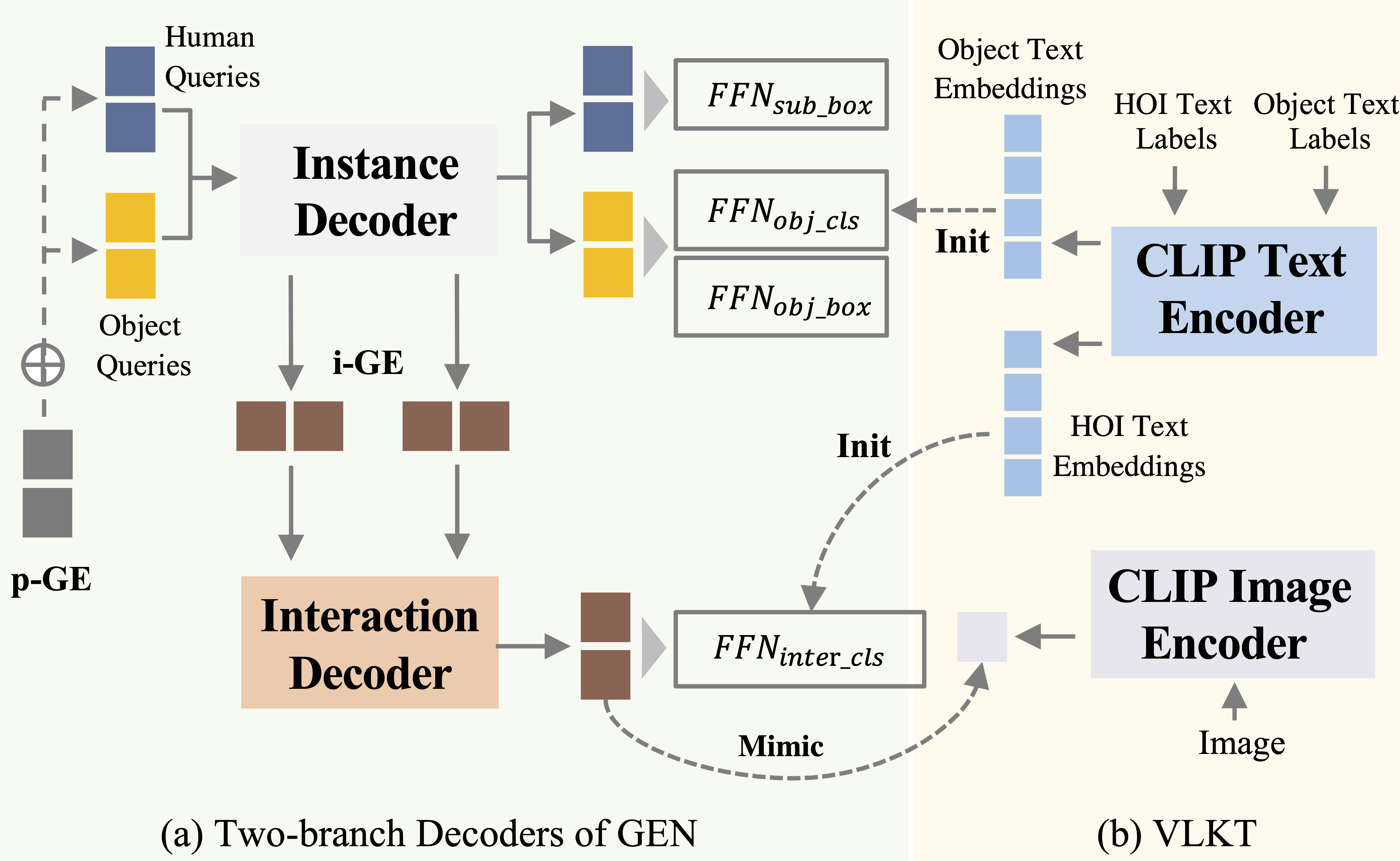
The task of Human-Object Interaction~(HOI) detection could be divided into two core problems, i.e., human-object association and interaction understanding. In this paper, we reveal and address the disadvantages of the conventional query-driven HOI detectors from the two aspects. For the association, previous two-branch methods suffer from complex and costly post-matching, while single-branch methods ignore the features distinction in different tasks. We propose Guided-Embedding Network~(GEN) to attain a two-branch pipeline without post-matching. In GEN, we design an instance decoder to detect humans and objects with two independent query sets and a position Guided Embedding~(p-GE) to mark the human and object in the same position as a pair. Besides, we design an interaction decoder to classify interactions, where the interaction queries are made of instance Guided Embeddings (i-GE) generated from the outputs of each instance decoder layer. For the interaction understanding, previous methods suffer from long-tailed distribution and zero-shot discovery. This paper proposes a Visual-Linguistic Knowledge Transfer (VLKT) training strategy to enhance interaction understanding by transferring knowledge from a visual-linguistic pre-trained model CLIP. In specific, we extract text embeddings for all labels with CLIP to initialize the classifier and adopt a mimic loss to minimize the visual feature distance between GEN and CLIP. As a result, GEN-VLKT outperforms the state of the art by large margins on multiple datasets, e.g., +5.05 mAP on HICO-Det. The source codes are available at https://github.com/YueLiao/gen-vlkt.
PDF Abstract CVPR 2022 PDF CVPR 2022 Abstract


 HICO-DET
HICO-DET
 V-COCO
V-COCO

