Boosting Standard Classification Architectures Through a Ranking Regularizer
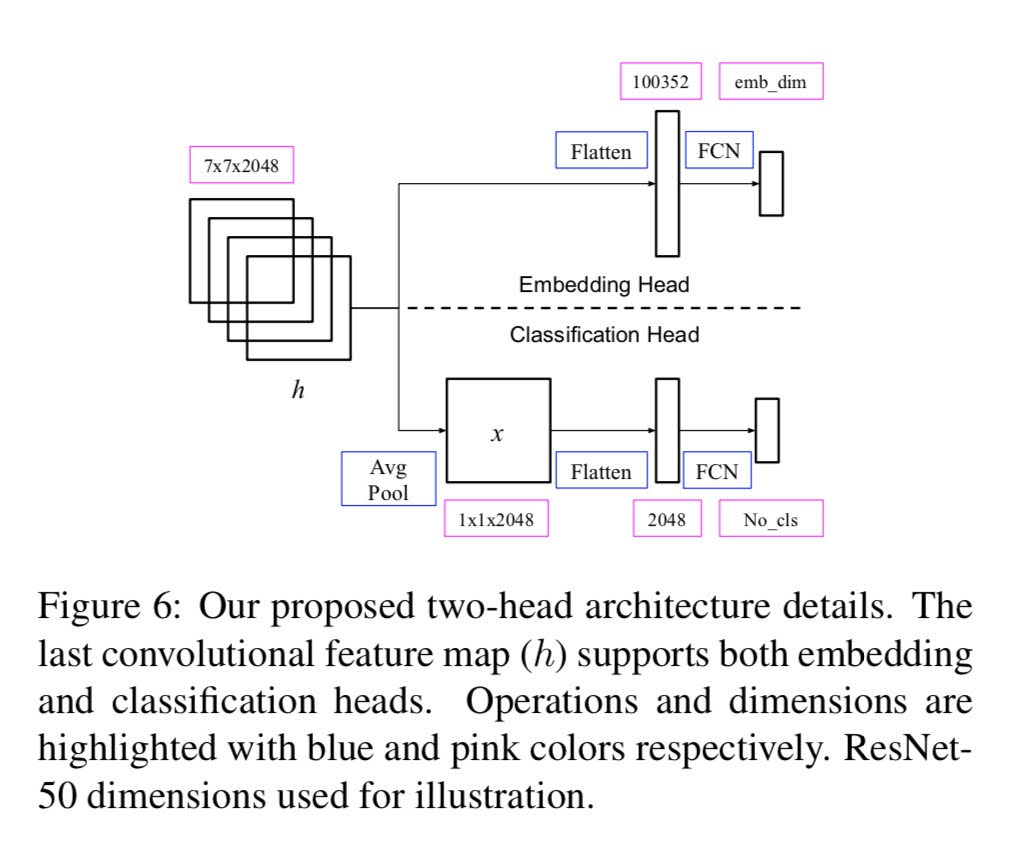
We employ triplet loss as a feature embedding regularizer to boost classification performance. Standard architectures, like ResNet and Inception, are extended to support both losses with minimal hyper-parameter tuning. This promotes generality while fine-tuning pretrained networks. Triplet loss is a powerful surrogate for recently proposed embedding regularizers. Yet, it is avoided due to large batch-size requirement and high computational cost. Through our experiments, we re-assess these assumptions. During inference, our network supports both classification and embedding tasks without any computational overhead. Quantitative evaluation highlights a steady improvement on five fine-grained recognition datasets. Further evaluation on an imbalanced video dataset achieves significant improvement. Triplet loss brings feature embedding characteristics like nearest neighbor to classification models. Code available at \url{http://bit.ly/2LNYEqL}.
PDF Abstract


 ImageNet
ImageNet
 Oxford 102 Flower
Oxford 102 Flower
 Stanford Cars
Stanford Cars
 NABirds
NABirds
 HDD
HDD
