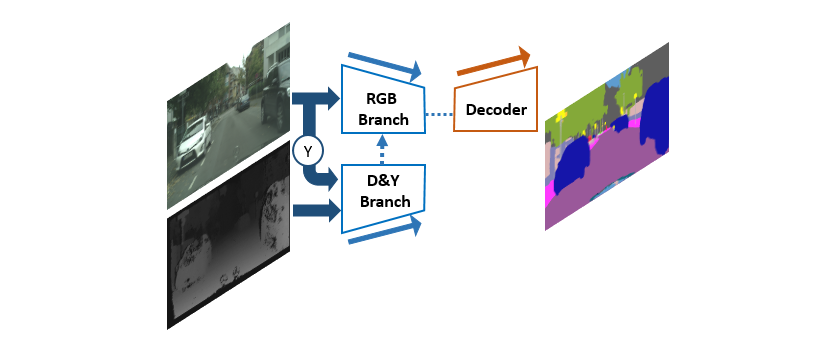
Incorporating Luminance, Depth and Color Information by a Fusion-based Network for Semantic Segmentation
Semantic segmentation has made encouraging progress due to the success of deep convolutional networks in recent years. Meanwhile, depth sensors become prevalent nowadays, so depth maps can be acquired more easily. However, there are few studies that focus on the RGB-D semantic segmentation task. Exploiting the depth information effectiveness to improve performance is a challenge. In this paper, we propose a novel solution named LDFNet, which incorporates Luminance, Depth and Color information by a fusion-based network. It includes a sub-network to process depth maps and employs luminance images to assist the depth information in processes. LDFNet outperforms the other state-of-art systems on the Cityscapes dataset, and its inference speed is faster than most of the existing networks. The experimental results show the effectiveness of the proposed multi-modal fusion network and its potential for practical applications.
PDF AbstractCode





Datasets
 Cityscapes
Cityscapes
Results from the Paper

| Task | Dataset | Model | Metric Name | Metric Value | Global Rank | Benchmark |
|---|---|---|---|---|---|---|
| Semantic Segmentation | Cityscapes test | LDFNet | Mean IoU (class) | 71.3 | # 73 | |
| Real-Time Semantic Segmentation | Cityscapes test | LDFNet | mIoU | 71.3% | # 27 | |
| Frame (fps) | 18.4 (1080Ti) | # 22 | ||||
| Real-Time Semantic Segmentation | Cityscapes val | LDFNet | mIoU | 68.48% | # 8 | |
| Semantic Segmentation | Cityscapes val | LDFNet | mIoU | 68.48% | # 76 |
