Learning to Generate Scene Graph from Natural Language Supervision
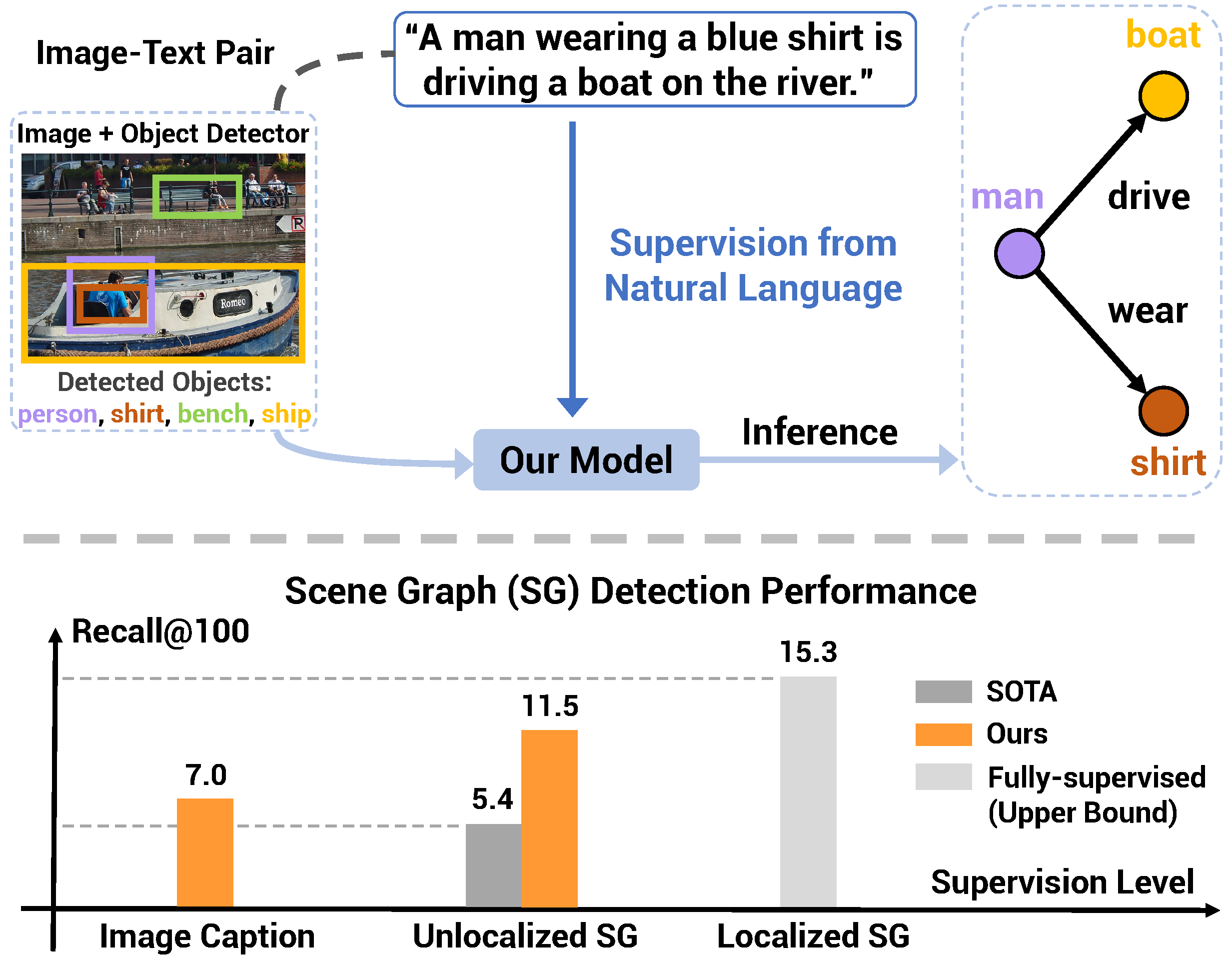
Learning from image-text data has demonstrated recent success for many recognition tasks, yet is currently limited to visual features or individual visual concepts such as objects. In this paper, we propose one of the first methods that learn from image-sentence pairs to extract a graphical representation of localized objects and their relationships within an image, known as scene graph. To bridge the gap between images and texts, we leverage an off-the-shelf object detector to identify and localize object instances, match labels of detected regions to concepts parsed from captions, and thus create "pseudo" labels for learning scene graph. Further, we design a Transformer-based model to predict these "pseudo" labels via a masked token prediction task. Learning from only image-sentence pairs, our model achieves 30% relative gain over a latest method trained with human-annotated unlocalized scene graphs. Our model also shows strong results for weakly and fully supervised scene graph generation. In addition, we explore an open-vocabulary setting for detecting scene graphs, and present the first result for open-set scene graph generation. Our code is available at https://github.com/YiwuZhong/SGG_from_NLS.
PDF Abstract ICCV 2021 PDF ICCV 2021 Abstract

 Visual Genome
Visual Genome
 VRD
VRD
 Objects365
Objects365
