Less is More: Consistent Video Depth Estimation with Masked Frames Modeling
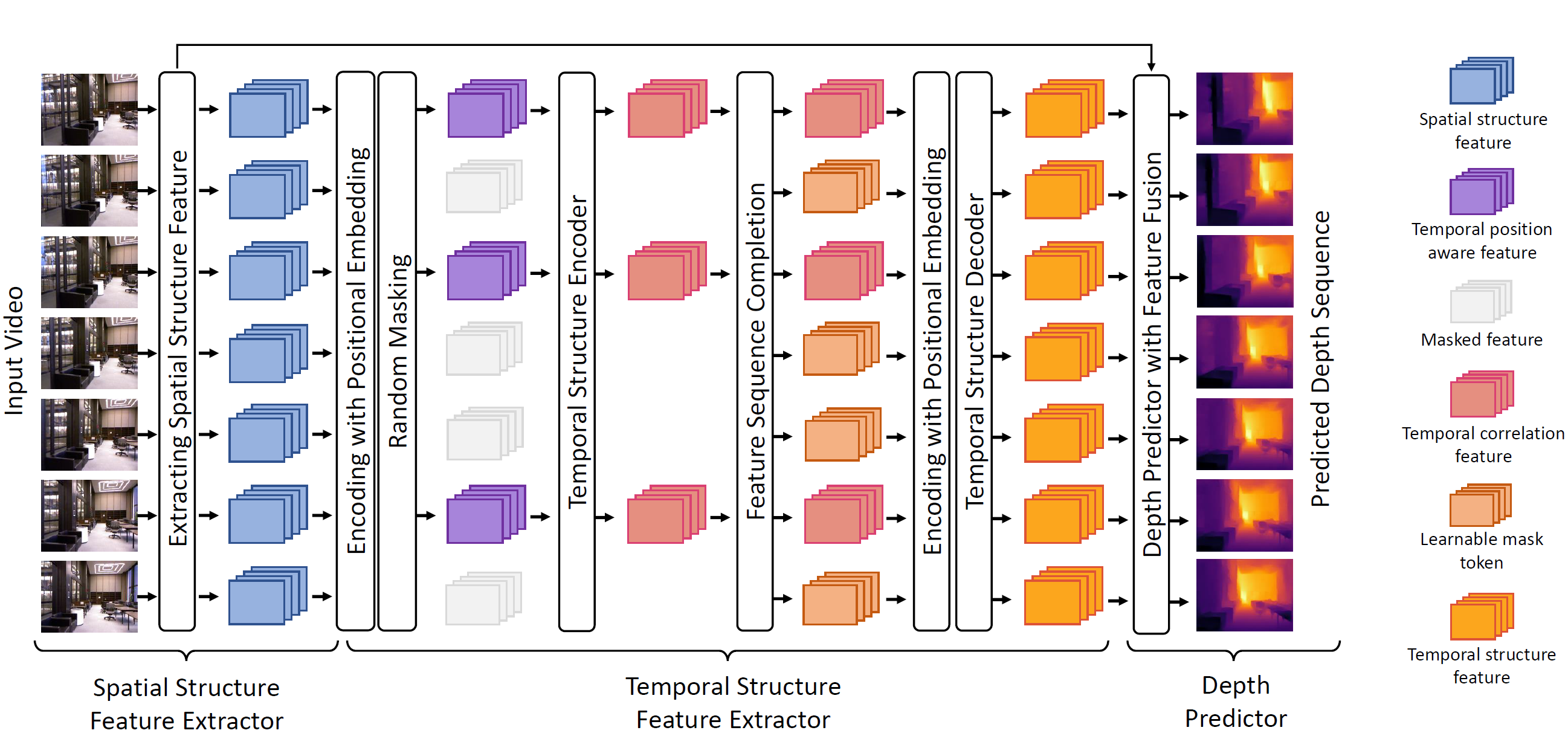
Temporal consistency is the key challenge of video depth estimation. Previous works are based on additional optical flow or camera poses, which is time-consuming. By contrast, we derive consistency with less information. Since videos inherently exist with heavy temporal redundancy, a missing frame could be recovered from neighboring ones. Inspired by this, we propose the frame masking network (FMNet), a spatial-temporal transformer network predicting the depth of masked frames based on their neighboring frames. By reconstructing masked temporal features, the FMNet can learn intrinsic inter-frame correlations, which leads to consistency. Compared with prior arts, experimental results demonstrate that our approach achieves comparable spatial accuracy and higher temporal consistency without any additional information. Our work provides a new perspective on consistent video depth estimation. Our official project page is https://github.com/RaymondWang987/FMNet.
PDF Abstract


 NYUv2
NYUv2
